|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna
2013, ročník 24, číslo 1, s. 79-88
Mgr. Václav Rosecký, Ing. Petr Žabička / Moravská zemská knihovna v Brně
Resumé:
V roce 2010 Moravská zemská knihovna zprovoznila VuFind, open source knihovní katalog, který se může stát základem pro plnohodnotný discovery systém. Článek popisuje tuto instalaci včetně vlastních vylepšení a formuluje takové požadavky na knihovní systém, aby se mohl snadno integrovat s discovery systémem. Je popsáno rozhraní definované Federací digitálních knihoven (DLF) pro tuto oblast a jeho výhody nebo omezení ve skutečném provozu.
Klíčová slova: VuFind, Aleph, OPAC, Solr, discovery systém, DLF API
Summary:
In 2010 The Moravian library in Brno put into operation VuFind, an open source library resource portal which may become a basis for a fully-developed discovery system. The article describes the system installation including VuFind enhancements developed by the library staff and the requirements a library system must meet to integrate easily with a discovery system. Further the text deals with the API (application programming interface) standardized by the Digital Library Federation – its advantages, disadvantages and limitations observed during implementation.
Keywords: VuFind, Aleph, OPAC, Solr, discovery system, DLF API
Moravská zemská knihovna v Brně (dále též MZK) zveřejnila v říjnu 2011 knihovní katalog nové generace založený na open source systému VuFind1. Provoz systému VuFind je závislý na datech a službách poskytovaných knihovním systémem Aleph. V následujícím textu jsou tyto vazby podrobněji popsány a uspořádány do přehledu obecných požadavků, které by měl splňovat knihovní systém, aby mohlo být jeho webové rozhraní snadno nahrazeno nadřazeným discovery systémem integrujícím celou šíři informačních zdrojů, které může knihovna poskytovat. Standardizace na této úrovni v budoucnu usnadní zapojení jednotlivých knihovních systémů do centrálního portálu knihoven, jehož vznik předpokládá Koncepce rozvoje knihoven ČR na léta 2011–2015 (Koncepce 2011–2015), schválená v roce 2012 vládou.
Integrace discovery a knihovních systémů
Moderní discovery systémy, jak je definuje například Marshal Breeding (Breeding 2012) jsou alternativou ke klasickému vyhledávacímu rozhraní v knihovních systémech.
Tyto systémy jsou uživatelsky přívětivé, umožňují jednoduché vyhledávání ve více zdrojích najednou a integrují prvky webu 2.0. Rozvoj informačních technologií tak umožňuje i odklon od dříve preferovaného federativního vyhledávání, jehož hlavní nevýhodou je nemožnost efektivně kombinovat výsledky vyhledávání z jednotlivých paralelně prohledávaných databází.
Integrace tradičního knihovního systému do discovery systému umožní uživatelům opustit klasický webový OPAC2. Ten v mnoha aspektech (zejména svou složitostí) ustrnul na úrovni 90. let 20. století a neposkytuje uživateli komfort a logiku ovládání, na které je zvyklý z moderních webových aplikací. Náhrada jednoho webového rozhraní jiným však sama o sobě neřeší zapojení dalších informačních zdrojů, zejména placených bibliografických nebo fulltextových databází dostupných v dané knihovně, přímo do discovery systému. Proto i na knihovní systémy, které mají navenek uživatelské rozhraní podobné skutečným discovery systémům, v tomto článku nahlížíme stále jako na knihovní systémy, jejichž integrace do discovery systému může být žádoucí.
Uživatelům zpřístupňované informační zdroje můžeme rozdělit do tří základních kategorií:
Proto se často uplatňuje
Lokální index má výhodu ve větší flexibilitě, neboť ho lze snadno rozšiřovat o další funkce. V případě, že by mělo jít o portál sloužící většímu počtu knihoven, se například nabízí geolokační služby umožňující řešit dotazy typu, která knihovna v nejbližším okolí má hledanou knihu. Velkou výhodou centrálních indexů oproti lokálním je naopak jejich obsáhlost, neboť často indexují externí licencované zdroje včetně plných textů.
Možnosti integrace discovery systémů s knihovními systémy se liší. Některé systémy se omezují jen na základní funkcionalitu – na pouhou informaci, že v dané knihovně daný dokument existuje; při požadavku na výpůjčku či uživatelské konto je uživatel přesměrován do nativního rozhraní původního knihovního systému, což není po uživatelské stránce přívětivé. Jiné systémy, jako například VuFind nebo Primo, implementují důležitou či veškerou funkcionalitu OPACu. Jak si ukážeme dále, integrace knihovních systémů do rozhraní discovery systémů je podmíněna jejich vzájemnou kompatibilitou, resp. podporou shodných standardů.
Podrobnější porovnání výše zmíněných komerčních systémů lze najít v článku Zkušenosti služeb Národní knihovny s centrálními indexy a web-scale discovery systémy (Coufalová 2012).
Funkce vyžadované discovery systémem pro integraci s knihovním systémem
Standardní katalog knihovny nabízí uživatelům řadu služeb a funkcí, které je vhodné v nějaké podobě přenést do rozhraní discovery systému. Těmito základními funkcemi jsou:
Problémem při integraci knihovních a discovery systémů je nesourodost rozhraní těchto systémů. Většina knihovních systémů poskytuje vlastní proprietární rozhraní, která jsou navzájem nekompatibilní. Některé systémy dokonce neposkytují žádná rozhraní a případný přístup lze řešit jedině dotazy do SQL databáze či použitím techniky web scrapingu6, což je velmi nepohodlné a přináší komplikace při změně či aktualizaci SW. V polovině roku 2007 proto Digital Library Federation (dále DLF) ustavila skupinu pro analýzu vzájemné integrace knihovních a discovery systémů za účelem vytvoření technického návrhu rozhraní pro propojení těchto systémů. Výsledkem byl dokument ILS Discovery Interfaces (DLF 2008) obsahující technická doporučení pro tvůrce knihovních systémů. Dokument popisuje čtyři úrovně interoperability – je na tvůrci knihovního systému, aby si vybral úroveň, kterou chce implementovat. Přitom platí, že musí zahrnout všechny předchozí úrovně:
Důležité je zmínit, že dokument nepředepisuje, jak má vypadat rozhraní, ale jen doporučuje, jaké protokoly a datové standardy by bylo možné využít pro implementaci těchto funkcí. Například u metod pro práci s uživatelským kontem doporučuje NCIP či SIP protokol, zatímco u funkce HarvestBibliographicRecords pro sklízení záznamů doporučuje OAI-PMH protokol. Vzhledem k tomu, že se jedná o datově náročnou operaci, zmiňuje i metody typické pro daný knihovní systém.
Doporučená rozhraní v DLF API7
Použití otevřených rozhraní je důležité nejen pro integraci knihovních systémů s discovery systémy, ale i pro obecné otevření informačních systémů knihoven veřejnosti. Výše uvedená doporučení jsou tak v souladu s doporučeními JISC Open Bibliographic Data Guide (JISC 2010).
VuFind
VuFind je open source knihovní katalog vyvíjený Falvey Memorial Library na Villanova University. Dle slov jeho autorů se jedná o katalog vytvářený knihovnami pro knihovny. Vývoj systému VuFind započal v roce 2007. V roce 2009 tvůrci obdrželi ocenění od Mellonovy nadace spolu s finanční odměnou ve výši 50 000 dolarů a v druhé polovině roku 2010 byla uvedena verze 1.0. VuFind přináší uživatelům mimo jiné jednoduché vyhledávání s řazením dle relevance, zpřesňování výsledků fasetami, osobní prostor a našeptávač. Aplikace je napsaná v programovacím jazyce PHP, jako databázi používá MySQL či PostgreSQL, pro vyhledávání pak indexovací nástroj Solr. Aktuální verze je 1.3, připravuje se nová přepracovaná verze 2.0, která vyjde během roku 2013.
VuFind umožňuje zpřístupnění záznamů z lokálních i externích zdrojů v různých metadatových formátech. VuFind také pamatuje na uživatele mobilních zařízení a poskytuje jednoduché webové rozhraní přizpůsobené těmto zařízením. Plán vývoje projektu (roadmap) lze nalézt na stránkách projektu VuFind.
Solr
Solr je open source fulltextový vyhledávací nástroj napsaný v jazyce Java postavený nad fulltextovým jádrem Apache Lucene. Solr podporuje fasetovou navigaci, zvýrazňování hledaných výsledků, replikaci nebo rozdělení indexu na více serverů a distribuované vyhledávání. Replikace přitom umožňuje sdílet index mezi více servery a zajistit tak ochranu proti výpadkům v případě selhání, zatímco rozdělením indexu na více serverů je možné dosáhnout vyšší rychlosti vyhledávání ve velmi velkých indexech a distribuované vyhledávání pak slouží k vyhledávání v takto rozděleném indexu. Solr poskytuje rozhraní pro vyhledávání informací prostřednictvím webových služeb, takže jej lze snadno používat ve většině programovacích jazyků. Pro popis ukládaných dokumentů slouží schéma ve formátu XML, které určuje, co a jak se má indexovat. Např. titul můžeme zároveň "zaindexovat" několika způsoby do více polí a pro vyhledávání každému poli přiřadit jinou váhu:
Pro práci se záznamy ve formátu MARC používá VuFind nástroj SolrMarc, který umožňuje jejich fulltextovou indexaci do Solr. Proces se konfiguruje prostřednictvím textových souborů v jednoduchém formátu klíč=hodnota, kde klíč určuje index (autor, název atd.) a hodnota seznam polí, která se mají uložit. Komplikovanější případy lze řešit vlastním skriptem obsahujícím funkce, které jako parametr dostanou právě zpracovávaný záznam a vrátí hodnotu či seznam hodnot, jež se mají indexovat, a tyto funkce lze pak vyvolat z konfiguračního souboru. Příkladem konfiguračního souboru je např. uložení údajů o původcích díla – indexuje se zvlášť hlavní autor a zvlášť spoluautoři a při vyhledávání je hlavnímu autorovi přiřazena větší váha než spoluautorům:
author = 100abcd
author2 = 110ab:111ab:700abcd:710ab:711ab
Implementace systému VuFind v MZK
Implementace systému VuFind v MZK vychází ze standardní distribuce katalogu VuFind 1.3, která je doplněna o některá rozšíření vyvinutá v MZK. Jádrem těchto rozšíření je ovladač pro Aleph, který je popsán dále v této kapitole a který je podobně jako další rozšíření volně dostupný.
Z Alephu jsou pravidelně jednou denně exportovány aktualizace, které obsahují nové a změněné bibliografické záznamy obohacené o informace o exemplářích. Nadto jsou jednou týdně exportována veškerá bibliografická metadata ve formátu MARC ISO 2701 včetně informací o exemplářích, protože Aleph umí podchytit v denních aktualizacích změny jen na úrovni bibliografického záznamu, nikoli změny na úrovni exemplářů samotných. Protokol OAI-PMH zatím není používán, protože není vyřešeno předávání informací o změnách v exemplářích prostřednictvím tohoto protokolu. Z těchto exemplářů je totiž získáván údaj o dostupnosti dokumentu (zda je možno jej vypůjčit absenčně nebo jen prezenčně, zda jsou k dispozici dostupné exempláře či zda je dokument ve volném výběru), který je využit ve fasetě "typ výpůjčky". Typ výpůjčky "absenční" je přitom zároveň chápán i jako prezenční, přičemž v případě multiplikátů stačí alespoň jeden exemplář, který je absenční, aby byla dostupnost dokumentu nastavena jako absenční. Uživatel tak může filtrováním získat informace o knihách, které jsou ve volném výběru, a dostane se k nim tedy bez čekání. Faseta nebere v potaz, zda je exemplář momentálně vypůjčen či rezervován, neboť exportované záznamy tuto informaci neobsahují. V případě, že by se podařilo tuto informaci do exportovaných záznamů vkládat a aktualizace se předávaly častěji než jednou denně, bylo by možné uživatelům nabídnout možnost zobrazit si jen záznamy s exempláři, které jsou volné. Toto vylepšení bude možné realizovat po nasazení nové verze SolrMarc, který bude obsahovat Solr verze 4.0. Ten již podporuje atomickou aktualizaci, což umožní index aktualizovat velmi často, například každou hodinu.
Zobrazované záznamy jsou dále obohacovány o náhledy obálek a obsahy knih, které jsou přebírány ze serveru www.obalkyknih.cz. Naopak některé funkce, jako jsou rezervace knih pro vyučované předměty, nebyly implementovány, protože je MZK nepoužívá.
Schéma Solr bylo upraveno s ohledem na specifika českého jazyka – abecední řazení výsledků bylo nastaveno podle českých pravidel a byl odstraněn stemmer10 pro anglický jazyk. Stemmer pro český jazyk zatím nebyl implementován, v době přípravy tohoto článku probíhalo jeho testování. Testován je algoritmický stemmer pro češtinu, který je součástí Solr, a slovníkový stemmer Hunspell11 se slovníkem z OpenOffice, který ale bude před zahájením srovnávacích testů nutné upravit do funkční podoby.
Indexace byla obohacena o plné texty obsahů knih převzatých ze serveru www.obalkyknih.cz. Na základě naší připomínky byla do schématu Solr v systému VuFind doplněna dynamická pole, díky čemuž je možné přidávat do indexu další položky například pro vyhledávání či pro fasetu bez nutnosti editace schématu.
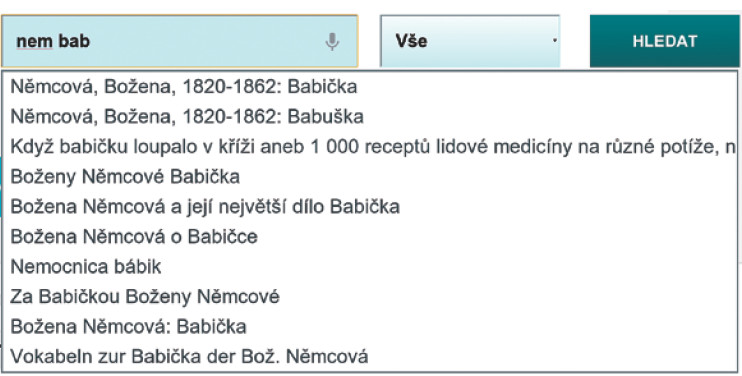
Klasický našeptávač, který při psaní dotazu do vyhledávácího pole průběžně nabízí nápovědu obsahující právě zadaný dotaz, dával nerelevantní výsledky. Napovídač12 MZK indexuje jméno autora, název díla a předmětová hesla z exportu ve formátu MARC do Solr a poskytuje webovou službu, která vrací výsledky ve formátu JSON13 seřazené podle počtu výskytů. Tento napovídač lze integrovat do libovolných jiných systémů, jako je katalog či webové stránky knihovny. Na obrázcích 1 a 2 je možné srovnat nabídku napovídače MZK (obr. 1) a napovídače system VuFind pro dotaz "nem bab".
Obr. 1 Napovídač vyvinutý v MZK (archiv autora)
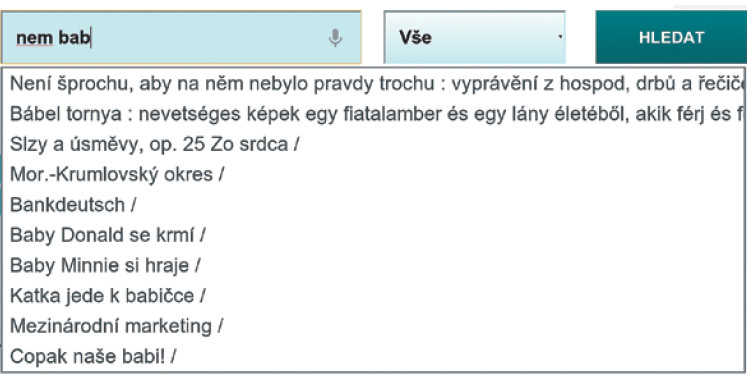
Obr. 2 Původní napovídač system VuFind (archiv autora)
Během roku 2012 MZK testovala zapojení centrálních indexů (Primo Central, EDS a Summon) do VuFind. V současné době pokračuje testování aplikace Blender od společnosti ExLibris. Tato aplikace integruje výsledky vyhledávání z Primo Central a lokálního indexu z VuFind.
Přihlašování uživatelů je řešeno prostřednictvím Shibbolethu, implementace .....Shibbolethu ve VuFind byla z naší strany rozšířena o podporu globálního odhlášení14 a předávání vybraných atributů uživatele (e-mailová adresa, jméno atd.) zpět do systému VuFind.
Pro práci s výpůjčkami a čtenářským kontem bylo využito webových služeb systému Aleph. Ten poskytuje dvě rozhraní:
Rozhraní RESTful API je dostupné v Alephu od verze 18, X Services již od verze 14, proto se funkcionalita X Services a RESTful API v některých případech překrývá. Nevýhodou X Services oproti RESTful API je nutnost vlastnit licenci na něj a platit každoroční poplatek firmě ExLibris. Originální ovladač pro Aleph poskytoval ve VuFind omezenou funkcionalitu, proto byl podstatně rozšířen tak, aby implementoval všechny funkce vyžadované systémem VuFind. X Services jsou používány jen pro zjišťování dostupnosti jednotky a pro "překlad" čárového kódu na název báze a systémové číslo, pro ostatní funkce je použito služeb RESTful API. Ovladač lze použít i bez X Services, pokud se pro autentizaci čtenářů použije LDAP či Shibboleth; pro překlad čárových kódů lze použít index zmíněného vyhledávacího nástroje Solr a pro zjištování dostupnosti pomalejší funkci z RESTful API. Ovladač vyvinutý v MZK se stal součástí VuFind 2.0; verze 1.3 jej neobsahuje kvůli zachování kompatibility se starším ovladačem.
Koncem roku 2011 byla v MZK spuštěna nová podoba VuFind, která respektuje jednotný grafický vzhled instituce. V polovině července 2012 bylo v systému VuFind zpřístupněno procházení rejstříků, faseta dostupnost byla rozšířena o možnost vyfiltrovat knihy, které jsou dostupné v rámci projektu EOD15, a byla přidána dočasná schránka pro ukládání záznamů.
V rámci projektu Národní knihovny ČR a Moravské zemské knihovny v Brně "Vytvoření Národní digitální knihovny" je s nástrojem VuFind počítáno jako se systémem zajišťujícím zpřístupnění informačních zdrojů obou knihoven. I z tohoto důvodu je plánována častější aktualizace indexu, kdy by byl do údaje o dostupnosti zahrnut i aspekt absence exempláře z důvodu výpůjčky. Pro sklízení záznamů se bude používat OAI rozhraní systému Aleph. Vzhledem k tomu, že katalog MZK obsahuje značné množství starých map, připravuje se také rozšíření nástroje VuFind o možnost hledání v mapách podle geografických souřadnic.
VuFind na druhou stranu řeší jen otázku zpřístupnění fondů knihoven. Deduplikací či FRBRizací se zabývá jen na úrovni zpřístupnění, samotné obohacení bibliografických záznamů o informace potřebné pro deduplikaci či o identifikátory potřebné pro FRBRizaci ponechává na externích nástrojích16.
Z hlediska doporučení Federace digitálních knihoven (DLF) tak implementace nástroje VuFind v MZK splňuje všechny požadavky první úrovně (tj. sklízení bibliografických záznamů a informací o exemplářích, zjišťování dostupnosti a možnost odkazovat na daný záznam v systému Aleph), naopak většinu funkcí druhé úrovně zajišťuje VuFind vlastními prostředky a není proto nutné pro jejich realizaci využívat rozhraní Alephu (které však tyto funkce také podporuje). Jedná se zde o funkce spojené s vyhledáváním a s jeho výsledky, kde VuFind pracuje s již sklizenými bibliografickými záznamy, které obsahují i všechny potřebné informace o exemplářích. Jedinou zatím nezprovozněnou funkcionalitou z této úrovně je sklízení autoritních záznamů. VuFind sám práci s autoritními záznamy podporuje, její testování v MZK bude teprve zahájeno. Z funkcionality třetí úrovně (funkce spojené s půjčováním dokumentů) podporuje Aleph všechny specifikované funkce s výjimkou rezervace titulu (kterou by bylo možné doprogramovat ve VuFind), podporována je jen rezervace exempláře. VuFind MZK využívá většinu funkcí třetí úrovně (byť autentizace uživatele probíhá prostřednictvím Shibbolethu a nikoli přímo skrze API Alephu) s výjimkou funkcí týkajících se požadavku na předčasné vrácení dokumentu17. Tyto možnosti MZK svým uživatelům nenabízí, podobně jako funkci prohledávání knih rezervovaných pro vyučované předměty, která je specifikována ve čtvrté úrovni DLF API.
Další vývoj
Moravská zemská knihovna v Brně postupně přechází na VuFind jako na svůj primární webový katalog. Další práce na systému VuFind budou v MZK proto zaměřeny zejména na jeho drobná vylepšení, tak, aby se mohl stát plnohodnotnou náhradou webového rozhraní systému Aleph. Dále MZK připravuje zprovoznění samostatné instance VuFind jako souborného katalogu starých tisků. Zde je knihovna motivována snahou zajistit uživatelům z jednoho místa přístup k exemplářovým popisům historických fondů různých institucí.
V úvodu zmíněná Koncepce rozvoje knihoven navrhuje centrální portál, který bude zastřešovat katalogy českých knihoven včetně knihoven digitálních a externí elektronické zdroje. Z hlediska možností integrace lokálních knihovních systémů je VuFind jedním z možných kandidátů na centrální portál, protože s příchodem nové verze VuFind 2.0 (Katz 2010) bude v systému dostupná i nativní podpora pro více knihoven či konsorcií.
Bylo by nanejvýš vhodné, aby knihovní systémy v ČR zpřístupnily své služby s použitím otevřených a široce podporovaných standardů a aby se tak centrální portál knihoven mohl stát realitou. Příkladem může být právě se rozbíhající projekt Národní digitální knihovny ve Finsku18, jenž také počítá s centrálním portálem zastřešujícím více knihoven s různorodými knihovními systémy a postaveným na systému VuFind.
Poznámky
2 OPAC (Online Public Access Catalog) – online veřejně přístupný katalog knihovny.
6 Počítačová metoda automatické extrakce informací z webových stránek.
7 Application Programming Interface – rozhraní pro automatizovanou komunikaci s jinými systémy.
8 Representational state transfer – bezestavové rozhraní nad HTTP pro snadný přístup k datům. REST je založeno na zdrojích, na které se odkazuje globálním identifikátorem (např. URL), a prostřednictvím HTTP protokolu je s nimi možné manipulovat. REST za tímto účelem definuje 4 metody pro přístup ke zdrojům – pro získání, vytvoření, smazání a změnu (z anglického CRUD – create, read, update and delete).
9 http://www.gbv.de/wikis/cls/DAIA_-_Document_Availability_Information_API
10 Stemmer slouží pro převod skloňovaného slova do jeho základního tvaru.
11 Dostupný z http://hunspell.sourceforge.net/.
12 Zdrojové kódy dostupné na: https://github.com/moravianlibrary/Autocomplete.
13 JavaScript Object Notation – datový formát používaný Javascriptem.
14 Jediným odhlášením je uživatel odhlášen ze všech serverů, na kterých byl prostřednictvím Shibbolethu v daném okamžiku přihlášen.
15 eBooks on Demand – E-knihy na objednávku. Služba umožňuje uživatelům objednat digitální kopii knihy, která již není chráněna autorskými zákony, za poplatek.
16 Například nástroj vycházející z http://www.loc.gov/marc/marc-functional-analysis/tool.html.
17 Uživatel může zadat zpoplatněný prioritní požadavek na výpůjčku a knihovna se pokusí dokument od čtenáře, který ho má pravě půjčený, získat, třeba za nabídnutí nějaké výhody.
18 Bližší informace dostupné na http://www.kdk.fi/en/public-interface.
Použitá literatura
ANSI/NISO Z39.83-1-2012. NISO Circulation Interchange Protocol. [online]. Baltimore: NISO, 2012. [cit. 2012-4-9]. Dostupné z: http://www.niso.org/workrooms/ncip/.
BREEDING, Marshal. Library web-scale. Computers in libraries. 2012, January/February, s. 19–21. ISSN 1041–7915.
COUFALOVÁ, Jindřiška, KOŠŤÁLOVÁ, Karolína a ŠŤASTNÁ, Petra. Zkušenosti služeb Národní knihovny s centrálními indexy a web-scale discovery systémy. Knihovna plus [online], 2012, 8(1) [cit. 2013-05-14]. ISSN 1801-5948. Dostupné z: http://knihovna.nkp.cz/knihovnaplus121/coufal.htm.
ILS Discovery Interfaces. [online]. Washington: Digital Library Federation, 2008 [cit. 2013-04-09]. Dostupné z: http://old.diglib.org/architectures/ilsdi/.
ISO 20775:2009. Information and documentation – Schema for holdings information. Geneva: International Organization for Standardization, 2009.
Open Bibliographic Data Guide. [online]. Bristol: JISC, 2010 [cit. 2012-2-13]. Dostupné z: http://obd.jisc.ac.uk/.
KATZ, Demian. VuFind 2.0: An Organizational & Software Roadmap. In: VuFind 2.0 Conference [online]. Villanova, 2010 [cit. 2013-04-09]. Dostupné z: http://vufind.org/docs/roadmap2.pdf.
LAGOZE, Carl a Herbert Van de SOMPEL. The Open Archives Initiative: Building a Low-Barrier Interoperability Framework. Roanoke: Proceedings of the first ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL‘01), 2001, s. 54. ISBN 1-58113-345-6.
Koncepce rozvoje knihoven ČR na léta 2011–2015 včetně internetizace knihoven: knihovny pro EVROPU 2020 [online]. 2012 [cit. 2013-04-10]. Dostupné z: http://knihovnam.nkp.cz/docs/koncepce2011-14/Koncepce_PIK_Rozp.doc?PHPSESSID=8fcd68d89e10591025f1fee72f129f2b.
SIP2. Standard Interchange Protocol. [online]. Saint Paul: 3M, 1993. [cit. 2012-4-9]. Dostupné z: http://multimedia.3m.com/mws/mediawebserver?mwsId=SSSSSu7zK1fslxtUm8_9m82Uev7qe17zHvTSevTSeSSSSSS--.
XML. Informace o dostupnosti lze vrátit na úrovni bibliografického záznamu (bez informace o dostupnosti jednotlivých exemplářů daného titulu) či na úrovni jednotek. Pro zjišťování dostupnosti však existuje více rozhraní, z nichž za zmínku stojí např. DAIA9 implementující jednoduché REST API, které vrací odpověď ve formátu XML či JSON a které je pro implementaci jednodušší než starší rozhraní pro dostupnost definované DLF API.
CITACE:
Rosecký, Václav a Žabička, Petr. Požadavky na výměnu dat mezi knihovním a discovery systémem na příkladu implementace systému VuFind v Moravské zemské knihovně. Knihovna [online]. 2013, roč. 24, č. 1, s. 79-88 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovna131/13179.htm>. ISSN 1801-3252.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |