|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna plus
2012, číslo 1
Jindřiška Coufalová, Karolína Košťálová, Petra Šťastná / Národní knihovna České republiky
Resumé:
Web-scale discovery systémy jsou užívány pro zpřístupnění dokumentů z různých zdrojů prostřednictvím jednoho vyhledávacího rozhraní. Základem těchto systémů jsou tzv. centrální indexy, které nahrazují federativní vyhledávání známé v ČR např. z Jednotné informační brány. Článek mapuje jednotlivé systémy a popisuje zkušenosti Národní knihovny ČR s implementací rozhraní EDS a Primo na datech knihovny a v rámci externí spolupráce.
Klíčová slova: centrální index - jednotný index - Národní knihovna ČR - integrace katalogu - web-scale discovery - EBSCO Discovery Service - Primo Discovery and Delivery - lokální Primo index - Summon - WorldCat Local - česká článková databáze ANL+ - Jednotná informační brána.
Summary:
Web-scale discovery services facilitate access to documents from heterogeneous library sources through a unified search interface. These systems are based on centralized indexes which replace federated searching, known in the Czech Republic e.g. from Uniform Information Gateway. The article maps particular systems and describes the National Library of the Czech Republic experience with an implementation of the EDS and Primo interfaces over its own as well as external library metadata.
Keywords: centralized index - unified single index - National Library of the Czech Republic - library collection integration - web-scale discovery - EBSCO Discovery Service - Primo Discovery and Delivery - local Primo index – Summon - WorldCat Local - Czech article database ANL+ - Uniform Information Gateway.
Jedním z cílů národního projektu Jednotné informační brány (dále JIB) byla od počátku integrace heterogenních zdrojů a poskytnutí paralelního vyhledávání v těchto zdrojích, které v současnosti probíhá převážně na základě protokolu Z39.50. Je zřejmé, že žádná technologie nemá navěky zajištěné své místo, u každého technického řešení je možné nalézt slabinu. Při paralelním vyhledávání může např. působit komplikace, pokud poskytovatel některého zapojeného zdroje změní jeho konfiguraci, přístupová práva, adresu nebo pokud je jeho z-server pravidelně přetížen. Tyto všechny drobné nepříjemnosti mohou u uživatelů zvyklých na vždy dokonalý a vše znalý Google vyvolávat nechuť potýkat se s takovým zdrojem opakovaně, raději se rozhodnou opustit služby knihovny.
Alternativou k systémům získávajícím data na základě federativního vyhledávání se v posledních letech stala řešení označovaná jako "web-scale discovery system", která jsou uživatelsky přívětivá, respektují požadavky Webu 3.0 a především v jednom rozhraní integrují pokud možno všechny zdroje knihovny, počínaje knihovními katalogy a konče elektronickými zdroji. Jejich výše zmíněná tvárnost je založena na skutečnosti, že hledání zde, oproti systémům s paralelním vyhledáváním, probíhá v jednotném indexu či rejstříku, do kterého jsou shromažďována data z licencovaných i volně dostupných elektronických informačních zdrojů. Data jsou získávaná již přímo od vydavatelů elektronického obsahu nebo od poskytovatelů jednotlivých licencovaných zdrojů. Tyto informace z elektronických informačních zdrojů pak bývají doplněny i údaji získanými z lokálních zdrojů (katalogy, digitální knihovny, repozitáře atd.). Na principu vyhledávání v jednotném indexu dnes funguje Primo Discovery and Delivery (ExLibris), Summon (Serials Solutions), EBSCO Discovery Service (EBSCO Publishing) nebo WorldCat Local (OCLC).
Web-scale discovery systémy umožňují knihovnám zajistit přístup k jejich sbírkám, zdrojům a službám za použití současných internetových technologií a konceptů. Tyto systémy mají podle Marshalla Breedinga čtyři charakteristické rysy (BREEDING, 2012):
Výběrem systémů tohoto typu se již zabývala řada knihoven, především zahraničních. V odborné literatuře je tak možné nalézt poměrně rozsáhlé články a statě popisující proces výběru, stanovení kritérií i samotné rozhodování. Při volbě systému zajisté hrají rozhodující roli dva faktory – jednak uživatelské rozhraní, jeho optimálnost pro koncové uživatele (jednoduchost ovládání v kombinaci komplexností nabízených služeb), a dále zajištění obsahu, který bude prostřednictvím tohoto systému uživatelům nabízen. Jak již bylo uvedeno, jádrem web-scale discovery systémů je index. Jeho tvorba je u každého producenta založena na odlišných principech a vazbách na "držitele" licencovaného obsahu. Relevanci uživatelského rozhraní může při běžném testování funkčních aplikací do značné míry posoudit i nezávislý hodnotitel, nicméně optimálnost obsahu centrálního indexu je schopna zvážit pouze konkrétní knihovna (např. srovnáním zdrojů integrovaných do centrálního indexu, ať již na úrovni databází či konkrétních dokumentů) s vlastním portfoliem. Vzhledem k faktu, že minimálně tři ze čtyř existujících centrálních indexů disponují API rozhraním a mohou být tedy zapojeny do "libovolného" rozhraní, volí některé knihovny i kombinace komerčního centrálního indexu s open source rozhraním, případně propojí dva komerční produkty.
Od roku 2008 se tým JIB aktivně zabývá testováním nových systémů, nejprve katalogů nové generace (POSPÍŠILOVÁ a kol., 2009), později v souvislosti s přípravou zadávací dokumentace pro projekt NDK i web-scale discovery systémů. Poslední testování proběhlo na podzim roku 2011 a jeho cílem bylo zjistit nové možnosti systémů na živých implementacích v zahraničních knihovnách. Pro každý ze systémů – Primo, Summon a EDS – byly nalezeny dvě volně dostupné implementace a u nich byl proveden test podle předem daných kritérií. Za realizační tým předkládáme ukázku dotazů a odpovědí:
| Hodnocení - slovní | |||
| Primo | Summon | EDS | |
| Využití stávajících systémů registrace uživatelů | ano | ne |
ne Objednat dokumenty z knihovního katalogu nelze, přihlášení do vlastního prostoru v rámci rozhraní není propojeno na databázi uživatelů (nutné vytvoření konta u EBSCO). |
| Prostor pro uživatele pro vlastní nastavení systému / vyhledávání / uchování výsledků | ano Možnost nastavení řazení, možnost volby jazyka a počtu výsledků na stránce, historie dotazů (chybí v ní však počet vrácených výsledků). Výborný košík, kam si lze ukládat zajímavé knížky, bez nutnosti se přihlásit. | ne Nastavení systému ano Dočasné uložení vybraných záznamů v Summon je pouze možné uložit si záznamy do schránky pro následný export, schránka trvá pouze po dobu aktuální session. |
ano Nutné vytvořit si konto u EBSCO, aplikace EDS NK ČR není v tomto směru propojena na existující databázi uživatelů; aplikace University of Georgia prostor pro uživatele nenabízí. |
| Podpora vzdáleného přístupu k licencovanému / volnému obsahu | ano | ano | ano |
| Vyhledávání může probíhat v celém obsahu indexu, pro přístup k licencovanému obsahu je nutné se autentikovat, ze záznamu nelze poznat, zda jde o dokument vyžadující autorizaci | |||
| Začlenění lokálních zdrojů do jednotného indexu | ano | ano | ano |
| Obohacování výsledků o informace z externích zdrojů | ano | ano | ano |
Toto testování je vždy z pohledu pracovníků knihovny a především služeb zajímavé. Umožňuje totiž seznámit se na funkčních aplikacích s novými trendy v této oblasti včetně celkové filozofie nastavení zdrojů a služeb pro koncové uživatele. Vzhledem k tomu, že testování vždy zatím probíhala z pohledu uživatele a nebylo možné se často dostat pod povrch těchto nastavení, bylo pro nás testování systémů na vlastních datech rozhodně důležitým doplněním k předchozím testům. Kromě přímého testování na vlastních datech je také podstatné zjistit připravenost těchto dat pro indexaci, harvesting a nastavení relevantních služeb. A právě o naše zkušenosti s implementací, testováním a provozem dvou systémů (EDS a Primo) bychom se rádi podělili. V článku dále naleznete základní informace o jednotlivých centrálních indexech, které jsou jádrem zmíněných web-scale discovery systémů, a to bez ohledu na fakt, zda jsme měli možnost je v rámci NK ČR vyzkoušet na vlastních datech nebo jako součásti jiných projektů, které NK ČR zastřešuje. Obecné charakteristiky indexů vycházejí z odborné literatury a informací volně dostupných na stránkách producentů, u systémů EDS a Primo Discovery and Delivery je pak podrobněji popsána jejich aplikace v rámci NK ČR.
Jednou ze služeb typu discovery je EBSCO Discovery Service (EDS) od společnosti EBSCO Publishing. Vývoj tohoto produktu začal v roce 2008, v následujícím roce proběhlo testování a ke zprovoznění došlo začátkem roku 2010. K lednu 2012 mělo službu implementováno 350 institucí po celém světě.
EDS je z velké části postavena na infrastruktuře a rozhraní, které připomíná databázové rozhraní EBSCOhost. To se poprvé objevilo v roce 1994. Přístup do EDS je poskytován na hostitelské platformě, není tedy nutná žádná místní instalace. V počátcích byla nutná registrace uživatelů pro využití EDS, v polovině roku 2010 byl zprovozněn také přístup typu host. Vzdálený přístup lze nastavit pomocí proxy serverů.
Základem pro vyhledávání je centrální index (uvádí se jako EDS Foundation Index nebo EDS Base Index, případně EDS Index). Tento index obsahuje metadata od desítek tisíc poskytovatelů obsahu (cca 20.000 producentů dat a 70.000 knižních vydavatelů), repozitáře typu open access (DOAJ, OAISTER, arXiv.org) a také různé lokální zdroje jednotlivých knihoven, tj. online katalogy knihoven, digitalizované sbírky či institucionální repozitáře. Zdroje mohou být založené na různých metadatových schématech (MARC, Dublin Core, XML či EAD). EDS pracuje s různými mechanizmy dodávání obsahu, ať už OAI-PMH nebo FTP. Nejsou stanoveny požadavky na minimální záznam. Metadata z integrovaných zdrojů jsou transformována do základního schématu EBSCOhost.
U zobrazených výsledků hledání lze zjistit, ze které z integrovaných databází záznam pochází. Centrální index tak má pro každou instituci vlastní nastavení, zohledňující její dostupné zdroje.
Neindexované zdroje mohou být prohledávány pomocí EBSCOhost Integrated Search (EHIS), nové technologie federativního vyhledávání. Výsledky se zobrazí ve sloupci vedle hlavního panelu, do kterého je lze následně promítnout.
Deduplikace záznamů probíhá na základě vlastního algoritmu, který vychází z analýzy citačních polí. Zůstává záznam s nejobsažnějšími daty, ostatní záznamy jsou dostupné v podrobném zobrazení tohoto záznamu.
Výsledky jsou řazeny podle relevance. Algoritmus zohledňuje obsah jednotlivých polí s důrazem na klíčová slova, předmětová hesla a autorský abstrakt. Dalšími faktory, které míru relevance ovlivňují, jsou aktuálnost či typ dokumentu (preference recenzovaných článků před recenzemi). Uživatel může do jisté míry ovlivnit, které prvky jsou pro něj prioritní a mají pro něj vyšší váhu v seznamu výsledků. Ke zpřesnění dotazu mohou být využity fasetové kategorie (typ zdroje, datové rozmezí, předmětová hesla či poskytovatel obsahu). Knihovna může také zažádat o upřednostnění některých lokálních zdrojů.
Pokud knihovna disponuje některými linkovacími nástroji, má možnost je aktivovat a v rámci EDS využívat. Příkladem může být aktivace SFX. Z nabídky producenta EDS lze takto aktivovat např. službu A-to-Z List. Podobně je možné přidat další doplňkové zdroje typu Google Scholar, Wikipedia. K dispozici je také rozhraní pro mobilní zařízení. EDS umožňuje využívat API rozhraní pro vlastní nastavení. Příkladem mohou být instalace Universitätsbibliothek Freiburg či Universitäts- und Stadtbibliothek Köln.
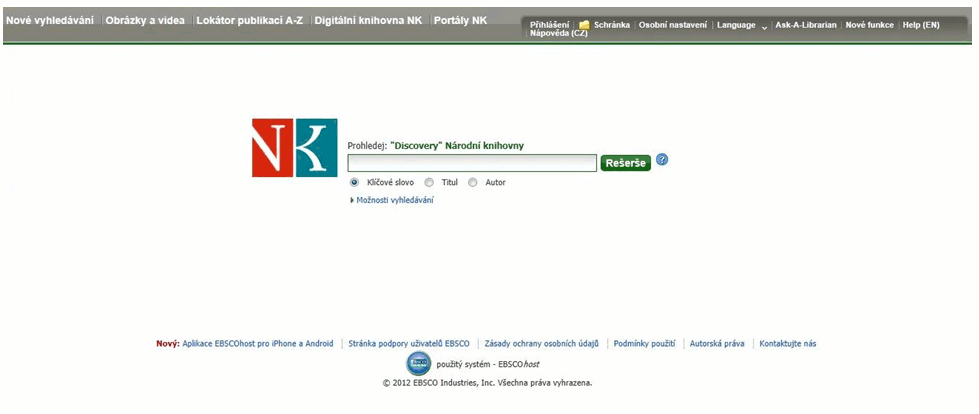
Obr. 1. Vstupní obrazovka EDS pro NK ČR
Národní knihovna ČR měla k dispozici zkušební přístup do EDS zhruba od srpna 2011 do ledna 2012. Nastavení a testování probíhalo už od jara 2011. Šlo především o nastavení lokálních zdrojů. V případě zkušebního přístupu NK ČR byl do EDS integrován elektronický katalog – báze NKC. Součástí centrálního indexu se stala také digitální knihovna Manuscriptorium; smlouva o jejím zpřístupnění v rámci nabídky produktů EBSCO Publishing byla s Národní knihovnou podepsána v květnu 2011.
Samotné integraci elektronického katalogu, báze NKC, předcházelo vyplnění dotazníku o technických aspektech. Dotazník zjišťoval, jaký systém knihovna využívá (Aleph verze 20), kolik obsahuje katalog bibliografických záznamů (1.950.000 záznamů), jak často budou zasílány aktualizace (přírůstky jednou týdně).
Další otázky se týkaly propojení na záznamy (URL syntax), metadat (jednoznačný identifikátor záznamu, jazyk, formát dat). Preferovaným formátem je MARC21, importovat lze i záznamy ve formátech UNIMARC, KORMARC či MARCXML. Záznamy NKC byly exportovány ve formátu MARCXML.
Dále se zjišťovalo, v jakých polích jsou uvedeny lokační údaje. V případě NKC byly tyto údaje převedeny do pole 996 ($h signatura, $l umístění). Další zjišťované údaje se týkaly identifikace elektronických a zvukových knih a dostupnosti plného textu (pole pro jednoznačnou identifikaci, limity pro vyhledávání podle typu dokumentu, propojovací pole na plné texty). Elektronické knihy v NKC jsou slovně specifikovány v poli 655 $a - elektronické knihy, zvukové knihy specifikovány nejsou, plný text je označen v poli 856 $y - Plný text. Pro zajištění dostupnosti v reálném čase může EDS navázat spojení s katalogem prostřednictvím protokolu Z39.50 na základě autentizačních parametrů (adresa serveru, port a jméno databáze).
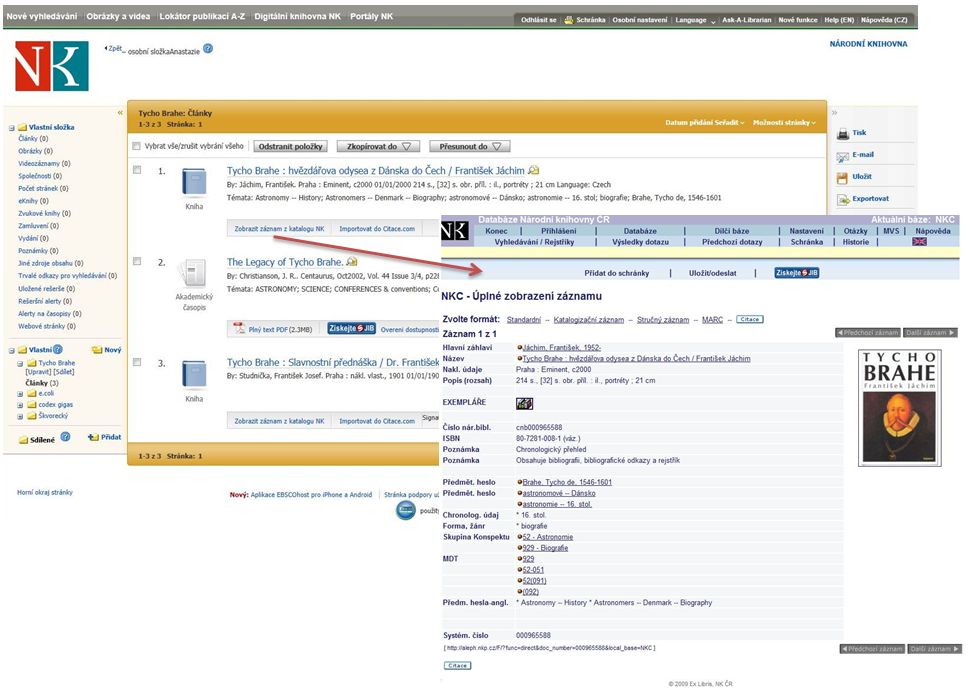
Obr. 2. Metadata z NKC v EDS s odkazem na záznam v bázi NKC
Uživatelsky přívětivým počinem je možnost integrovat vyhledávací okno v podobě skriptu na webové stránky instituce. Při zkušebním přístupu v NK ČR byla použita dvě vyhledávací okna, jedno pro registrované uživatele a druhé pro přístup typu host. Obě bylo možno využít jak z počítačové sítě v rámci knihovny, tak i prostřednictvím vzdáleného přístupu. Oba přístupy se lišily v dostupnosti zdrojů, především pak plných textů, které jsou vázány na licenční podmínky. Přihlášení do verze pro registrované uživatele bylo možné také v průběhu vyhledávání ve verzi typu host.
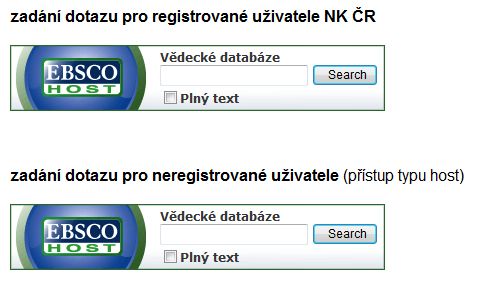
Obr. 3. Okna pro vyhledávání v EDS umístěná na stránkách NK ČR
Dostupnost plných textů ze zdrojů, které nejsou součástí databází EBSCOhost, byla možná po aktivaci propojení do konkrétních databází. Tímto způsobem byly pro NK ošetřeny přístupy do databází ScienceDirect, Wiley Online Library, SpringerLink či Web of Science (viz obr. 4).
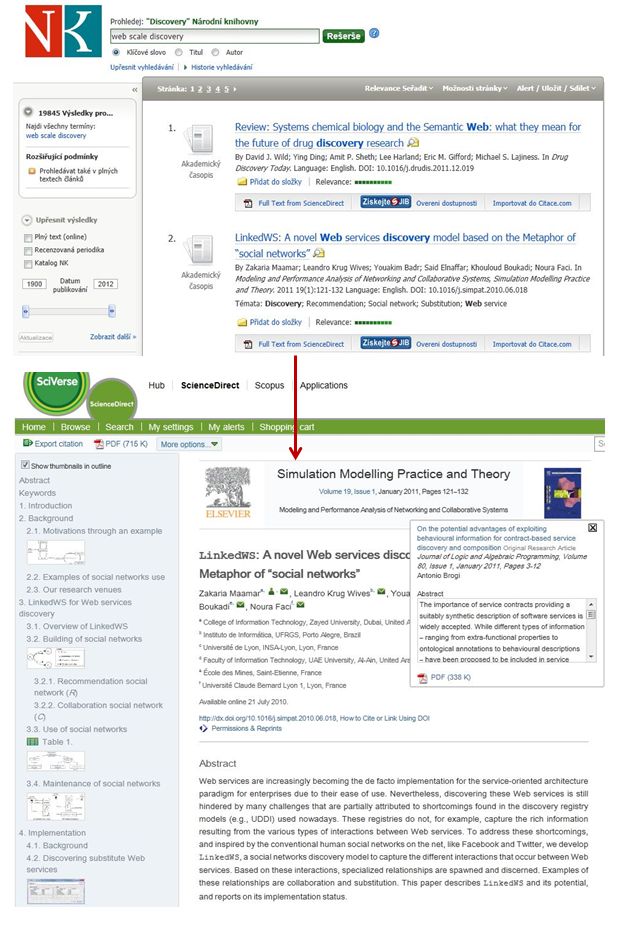
Obr. 4. Odkaz na plný text v databázi ScienceDirect
Podle dodaných dat bylo v době od března 2011 do ledna 2012 zaznamenáno 1.155 přístupů a bylo provedeno 161.134 rešeršních dotazů (podrobněji viz obr. 5).
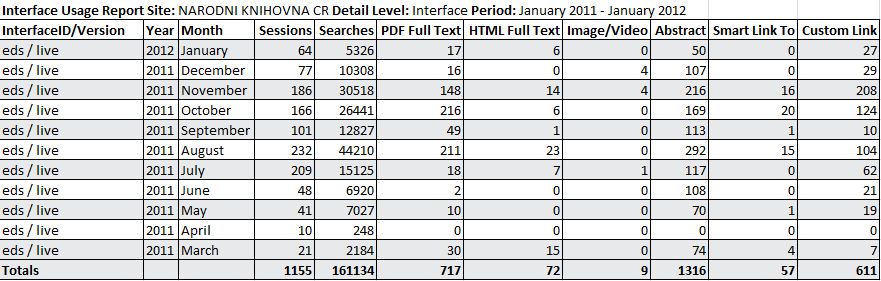
Obr. 5. Statistika přístupů do EDS v NK ČR
Ze statistických údajů lze také zjistit, jaký je poměr položených dotazů přes EDS ve srovnání s databázovým rozhraním EBSCOhost Research databases (viz obr. 6). Databáze EBSCOhost jsou v nabídce licencovaných zdrojů NK ČR již od roku 2000 a jejich využívání stále narůstá. V počtu dotazů na jeden vstup EDS převyšuje vyhledávání v databázovém rozhraní. V tom je ale zobrazeno více plných textů. Obě rozhraní se tak mohou významně doplňovat.
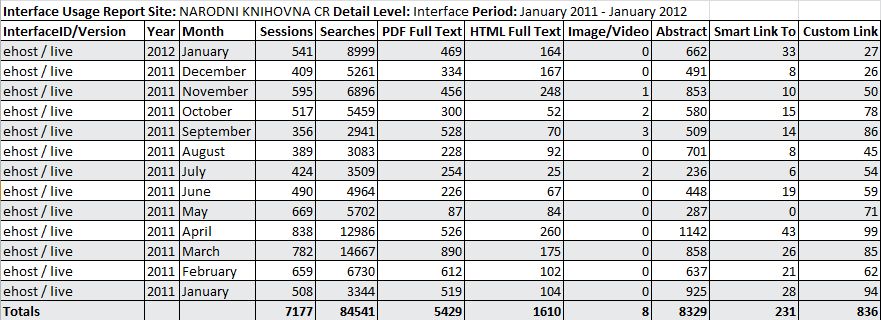
Obr. 6. Statistika přístupů do databázového rozhraní EBSCOhost
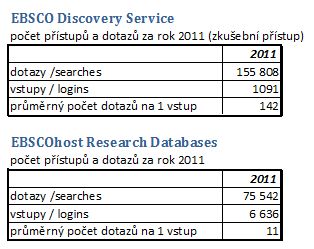
Obr. 7. Průměrný počet dotazů na jeden vstup – srovnání rozhraní ESD a databázové rozhraní EBSCOhost
Firma ExLibris představila Primo poprvé v roce 2007, verze 1.0 byla zveřejněna v květnu 2007. I na vývoji tohoto produktu se podílely knihovny z různých zemí. V současnosti využívá Primo Discovery and Delivery přes 900 zákazníků po celém světě.
Primo Discovery and Delivery (dále také jako Primo) funguje na principu dvou indexů, centrálního a lokálního. Údaje získané od primárních a sekundárních vydavatelů a agregátorů a informace z open access repozitářů jsou obsaženy v centrálním indexu nazývaném Primo Central. Tento index je vždy poskytován jako služba formou výpočetního oblaku. Primo Central se zaměřuje na vědecké publikace(časopisecké články, recenze, e-knihy, konferenční materiály, disertace) nabízené primárními a sekundárními vydavateli a agregátory.
Údaje z lokálních zdrojů knihovny jsou ukládány do tzv. lokálního indexu, sklízení zdrojů knihovny je vlastností rozhraní Primo. Tento index může zahrnovat např. záznamy z online katalogu knihovny, údaje z digitálních sbírek či institucionálních repozitářů. Pravidla pro sklízení a periodicitu sklízení si může knihovna stanovit individuálně, Primo podporuje různé metody pro sklízení a dodávání dat, včetně OAI-PMH a FTP. Je také schopno spolupracovat s řadou knihovních systémů a repozitářů a přijímat data v různých schématech, včetně MARC/MARC XML, Dublin Core, EAD. Sklizený obsah je normalizován do základního formátu systému Primo.
Vzhledem k tomu, že Primo získává záznamy z různých zdrojů, je zde používán proces, který pro potřeby vyhledávání duplicitní záznamy sloučí, při prezentování výsledků koncovému uživateli je pak uspořádává do skupin. Jako primární je pro zobrazování využíván záznam od vydavatele (pokud je v indexu dostupný).
Vyhledávání v Primo Discovery and Delivery probíhá souběžně v indexu vytvořeném z lokálních dat knihovny a v indexu Primo Central. Výsledky z obou indexů jsou sloučeny a uživateli prezentovány najednou.
Při hodnocení relevance využívá vlastní algoritmus, který pracuje s frekvencí výskytu hledaného pojmu, váhou pole, statistikou četnosti zobrazení/zpřístupnění daného záznamu, aktuálností. Algoritmus není omezen pouze na zmíněné parametry, za určitých okolností lze v relevanci dále zohledňovat, zda je titul recenzovaný. Knihovna si může definovat pravidla určující, které záznamy v nalezených výsledcích budou upřednostněny a posunuty v hodnocení relevance výše. Tento algoritmus může být např. založen na přiřazení důležitosti určitým polím v záznamu, lze také preferovat záznamy obsahující synonymum hledaného termínu. Pokud knihovna předplácí některou ze služeb pro obohacování záznamů, mohou být i tyto údaje, např. obsah (table of contents), při řazení dle relevance brány v potaz.
Pro vyhledávání Primo nevyžaduje autentizaci uživatele, knihovna si sama určí, v jaké fázi využívání bude po uživatele již jeho identifikaci požadovat, zpravidla tak může být učiněno před začátkem samotného vyhledávání nebo v okamžiku, kdy se uživatel snaží získat přístup k plnému textu. Primo spolupracuje s proxy severy či jinými autentikačními metodami, které knihovny využívají.
Do systému Primo mohou být integrovány i nástroje umožňující federativní prohledávání zdrojů, např. MetaLib, index Primo Central je také dostupný prostřednictvím API rozhraní (např. integrace Primo Central v prostředí Mango, Florida Gulf Coast University, či využití indexu Primo Central v kombinaci s rozhraním Blacklight v systém Virgo na University of Virginia).
V českém prostředí zatím není k dispozici rozhraní Primo Discovery and Delivery v ostrém nasazení nad sbírkami jedné či více knihoven. S tvorbou lokálního indexu a jeho využití prostřednictvím Primo se můžeme setkat u projektu ANL+, který je součástí Jednotné informační brány, druhou variantou zpřístupnění je klasické rozhraní JIB, které využívá možnosti MetaLib (paralelní vyhledávání založení na federativním vyhledávání).
Co vlastně ANL+ znamená?
ANL+ je experimentální zdroj poskytující informace o článcích publikovaných v českých novinách, časopisech a dalších pokračujících zdrojích od roku 2011. ANL+ navazuje na bázi ANL, kterou společně vytvářely od roku 1992 Národní knihovna České republiky, Moravská zemská knihovna v Brně, krajské knihovny a odborné knihovny.
ANL+ je plněna ze tří zdrojů, jednak bibliografickými záznamy z titulů, které jsou zpracovávány krajskými a odbornými knihovnami (bohatá metadata, která obsahují předmětová hesla, selekční prvky jsou provázány se soubory jmenných i věcných autorit, a která jsou dostupná všem volně, bez přímé vazby na plné texty). Dále obsah ANL+ tvoří tituly původně zpracovávané Národní knihovnou – variantní řešení pomocí externích zdrojů (NEWTON Media, a. s.). Tituly obsahují mimo velmi stručných a minimálně formalizovaných metadat i stručný náhled, plné texty a digitalizovanou podobu článků. Metadata i plné texty lze prohledávat a jsou společně se stručným náhledem dostupná všem volně, přístup k plným textům a digitalizované podobě článků vyžaduje registraci knihovny u dodavatele externího zdroje. Poslední částí jsou tituly původně zpracovávané Národní knihovnou – variantní řešení pomocí "vlastní" digitalizace. Tituly obsahují v porovnání s externím zdrojem bohatší metadata, stručný náhled, plné texty a digitalizovanou podobu článků. Metadata i plné texty lze prohledávat, přístup k plným textům a digitalizované podobě článků se řídí možnostmi a limity knihovní licence Autorského zákona. Ke zpřístupnění je využívána implementace systému Kramerius 4 v Moravské zemské knihovně.
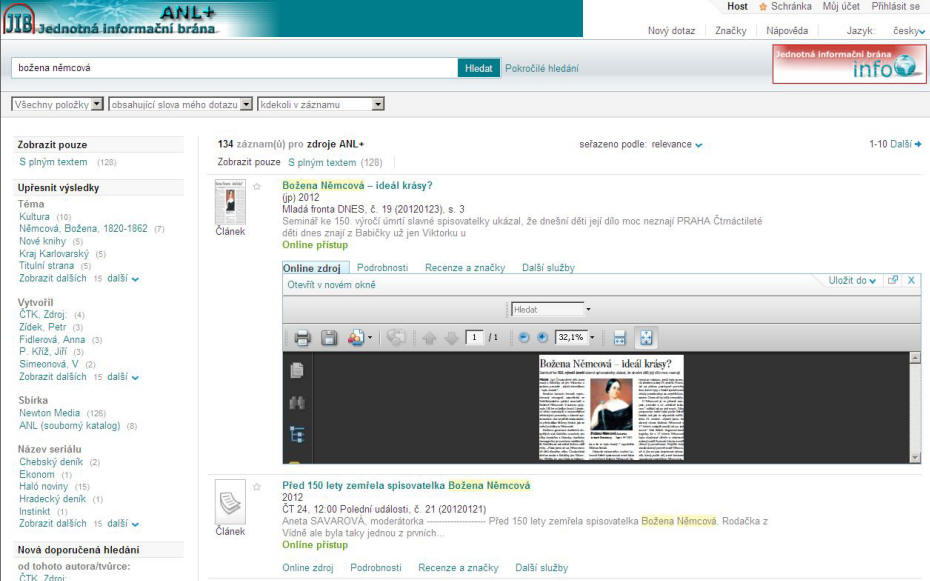
Obr. 8. ANL+ v rozhraní Primo
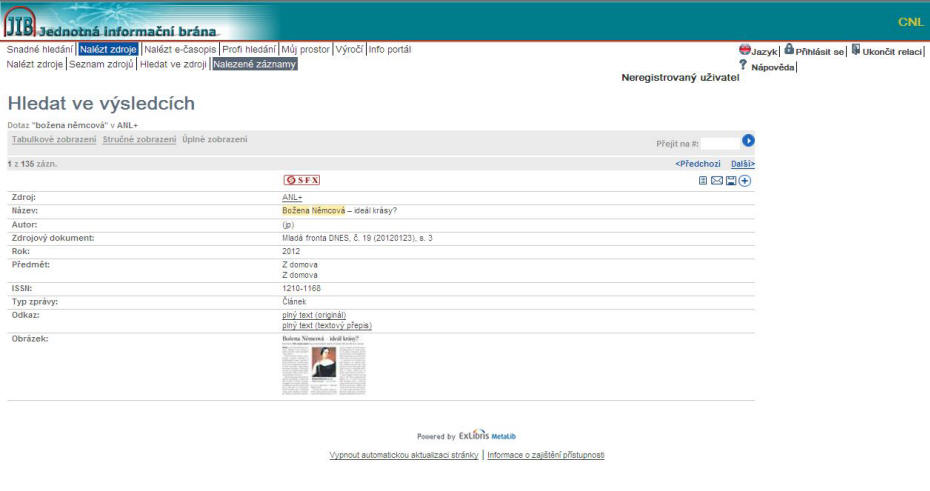
Obr. 9. ANL+ v rozhraní Jednotné informační brány
Z hlediska zpřístupnění je nejdůležitější částí tvorba lokálního indexu, který umožňuje koncovým uživatelům vyhledávání v jednom rozhraní a zobrazení relevantních výsledků vyhledávání v jedné množině. Lokální index je tvořen sklízením výše uvedených zdrojů pomocí OAI-PHM nebo pomocí FTP, kdy automatický a neustálý sběr dat ze všech zdrojů probíhá na pozadí. Sklizené záznamy se normalizují, aby bylo dosaženo jednoznačnosti, optimálního a přesného vyhledávání, přehledného zobrazení, možnosti třídění, přesného linkování, tvorby faset pro další navigaci a seskupování záznamů pro deduplikaci. Informace z různých zdrojů jsou v případě duplicit kombinovány a poskládány do jednoho výsledného záznamu, který může obsahovat mimo bibliografických údajů např. také stručný náhled, recenzi, obrázek titulní stránky či plný text a digitalizovanou podobu článků.
Během importu záznamů do lokálního indexu lze také volitelně upravit míru relevance jednotlivých dokumentů a zvýraznit významnější články (např. u recenzovaných titulů) nebo naopak snížit relevanci dokumentů, které pochází z méně podstatných zdrojů nebo jsou obsahově příliš krátké.
Lokální index na konci roku 2011 obsahoval celkem 812.975 záznamů, 28.509 záznamů spolupracujících knihoven, 368.307 záznamů z externího zdroje MediaSearch od firmy NEWTON Media, a. s., 416.126 záznamů z Anopress (do konce roku 2011 byl k dispozici i tento externí zdroj; v průběhu roku 2011 došlo ke sloučení obou firem a tedy i zdrojů) a 33 záznamů z vlastní digitalizace NK ČR (pilotní fáze odzkoušení na jednom periodiku). Je třeba uvést, že od roku 2012 projekt ANL+ využívá jen externí zdroj NEWTON Media, a. s., který dodává i rozpis titulů poskytovaných v roce 2011 Anopress (vzhledem k rozdílné metodice zpracování článků v obou externích zdrojích je celkový počet záznamů v roce 2012 o něco nižší než v roce 2011). Je potřeba také zdůraznit, že z externích zdrojů získávají knihovny i rozpisy zdrojů, které dříve nebyly k dispozici (televizní a rozhlasové relace). Část zdrojů (článků) přebíraných z externího zdroje se objevuje jen v elektronické podobě (např. deník Insider, Česká pozice), z toho vyplývá, že komerční agregátor (v našem případě NEWTON Media, a. s.) již umí dnes monitorovat i zdroje internetu a aktivity sociálních sítí.
Prostřednictvím rozhraní Primo bylo uživateli do konce ledna 2012 zadáno necelých 44 tisíc dotazů, prostřednictvím rozhraní JIB (využítí Quick Sets a přímé využití) necelých 13 tisíc dotazů. Z uvedených čísel vyplývá, že uživatelé preferují modernější a vstřícnější rozhraní. Tento požadavek není nijak překvapující a plně koresponduje s trendy v jiných českých i zahraničních knihovnách.
Primo Central uvolnila společnost ExLibris začátkem roku 2011. NK ČR se stala první institucí, která o aktivaci služby Primo Central požádala. Uživatelé Jednotné informační brány tak mohou od 21. února 2011 v prostředí Jednotné informační brány (JIB) využívat dvě konfigurace Primo Central. V tomto případě tedy není index Primo Central integrován přímo v "domovském" rozhraní Primo Discovery and Delivery, ale je propojen s rozhraním, které pro uživatele JIB poskytuje systém MetaLib.
Vzhledem k tomu, že bylo pro JIB možné vytvořit dvě konfigurace indexu Primo Central, rozhodli jsme se uživatelům JIB nabídnout pro vyhledávání index Primo Central jako celek (v prostředí JIB je tento zdroj označen jako Primo Central Free) a připravit i takovou variantu tohoto indexu, která by reflektovala pouze zdroje předplácené Národní knihovnou (v JIB je tento zdroj pojmenovaný Primo Central NK ČR).
Primo Central Free obsahuje tedy celý index Primo Central. Pro vyhledávání je tento zdroj v prostředí JIB volně přístupný všem zájemcům; bez požadavku na identifikaci uživatele se v JIB zobrazují i bibliografické informace o nalezených článcích. Plný text je samozřejmě dostupný pouze v případě, že originální databáze tento plný text nabízí zdarma nebo knihovna, z níž uživatel do JIB přistupuje, plný text předplácí.
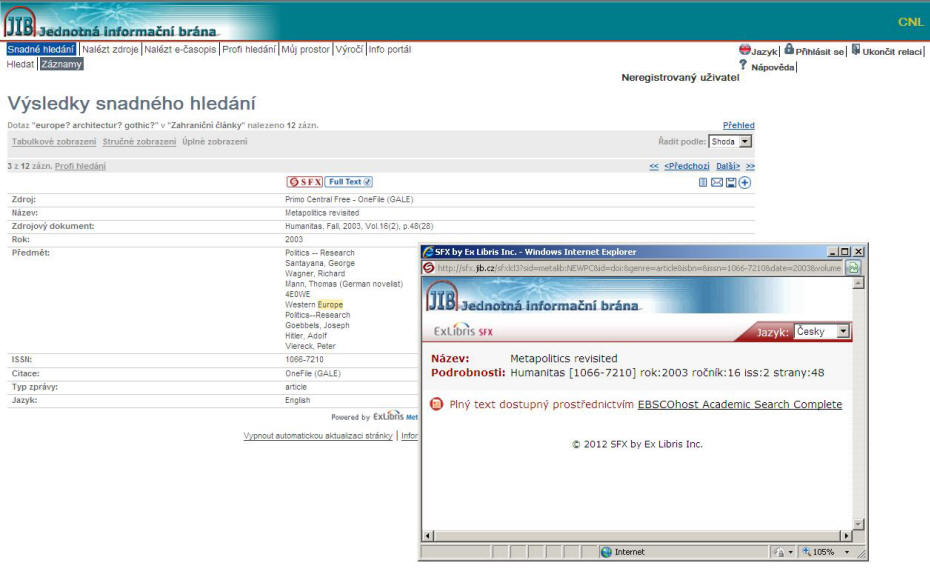
Obr. 10. Záznam článku nalezený v Primo Central Free v prostředí JIB
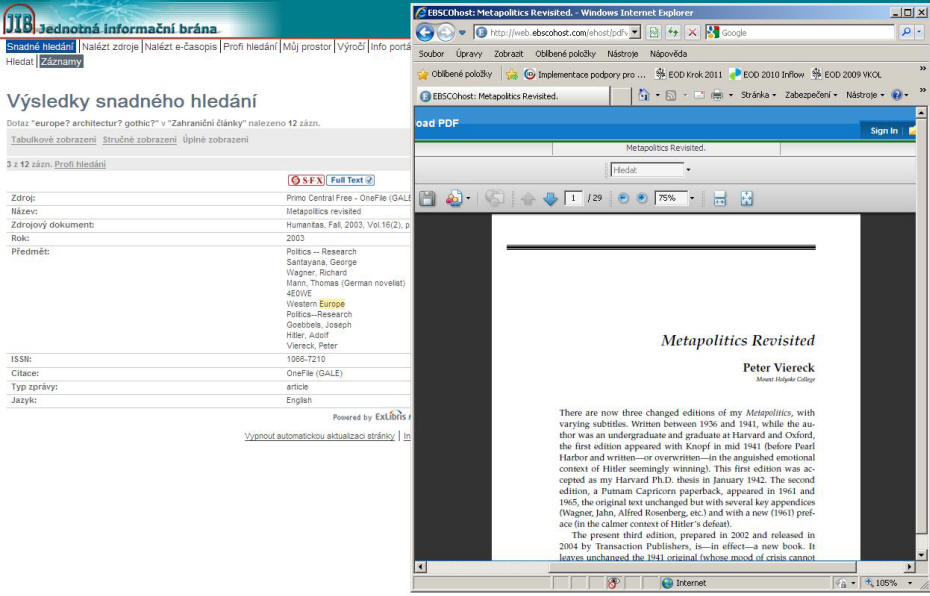
Obr. 11. Propojení záznamu nalezeného v Primo Central Free s plným textem v databázi EBSCO
V druhé konfiguraci indexu nazvané Primo Central NK ČR byly zdroje obsažené v Primo Central aktivovány výběrově tak, aby odpovídaly předplaceným EIZ v NK ČR. V současné době jsou v Primo Central NK ČR obsaženy údaje z databází Web of Science, SpringerLINK, JSTOR Music Collection, Music Online, Literature Resource Center, ebrary, Emerald Journals a řady hudebních databází vydavatelství Alexander Street Press. Obdobně jako ostatní licencované zdroje zapojené do JIB je Primo Central NK ČR možné v JIB využívat v případě, že do JIB uživatel vstupuje z oprávněné IP adresy (tj. IP adres NK ČR) a identifikuje se v JIB jako uživatele NK ČR prostřednictvím Shibboleth, případně využije vzdálený přístup NK ČR zajišťovaný systémem HAN.
V souvislosti s rozšiřováním obsahu indexu Primo Central je obsah Primo Central Free aktualizován automaticky, v Primo Central NK ČR jsou nově zapojené zdroje aktivovány "ručně", a to pouze v případě, že NK ČR má k danému licencovanému zdroji přístup.
Do 8. 2. 2012 položili uživatelé v JIB do obou konfigurací indexu Primo Central dohromady téměř 10.400 dotazů. Obě varianty indexu Primo Central naleznou uživatelé v rámci JIB na různých místech. Nejvíce viditelnými jsou pravděpodobně tzv. přednastavené skupiny zdrojů, které jsou v JIB užívány pro Snadné hledání. Skupina Zahraniční články obsahuje pouze Primo Central Free, skupina Zahraniční články – licencované je kombinací Primo Central NK ČR a dalších prohledatelných licencovaných databází (např. báze v rozhraní EBSCO). Další zdroje obsažené ve skupině Zahraniční články – licencované jsou prohledávány prostřednictvím Z39.50. Při zadání dotazu tedy uživatelé získávají v rámci jedné skupiny zdrojů jak záznamy nalezené v centrálním indexu, tak výsledky dodané pomocí federativního vyhledávání. Primo Central Free je v JIB dále zahrnuto v každé z předmětových kategorií Konspektu mezi obecnými zdroji, Primo Central NK ČR pak mezi oborovými zdroji v kategoriích zaměřených na knihovnictví a informační vědu (Všeobecnosti, Informatika) a hudbu. Primo Central Free i Primo Central NK ČR je uživatelům k dispozici také v Profi hledání, kde je při vyhledávání mohou kombinovat s dalšími zdroji, např. knihovními katalogy nebo volně dostupnými článkovými databázemi.
Společnost Serials Solutions začala vyvíjet vlastní nástroj typu discovery v roce 2008. Veřejně byl Summon ohlášen v lednu 2009, na vývoj systému se podíleli i další partneři a první beta verzi Summon zveřejnila Dartmouth College Library v červnu 2009. V Evropě zpřístupnila svou instalaci beta verze University of Liverpool Library téměř vzápětí poté, 6. července 2009. Celosvětově nyní Summon využívá 400 institucí.
Summon pracuje s jedním centralizovaným indexem, do něhož plyne obsah získávaný z komerčních i volných zdrojů. V oblasti licencovaného obsahu spolupracuje Summon s vydavateli a agregátory, cílem je získat oprávnění indexovat plný text přímo u poskytovatelů obsahu. Dále Summon indexuje a využívá strukturovaná metadata poskytovaná vydavateli a agregátory. Přehled vydavatelů, periodik a databázi zapojených do centralizovaného indexu Summon je dostupný na stránkách společnosti Serials Solutions.
Dalším zdrojem obsahu pro centralizovaný index Summon je indexace open access repozitářů a v neposlední řadě jsou součástí centralizovaného indexu Summon také data z lokálních sbírek knihoven, které Summon využívají. Tisková zpráva z 15. 12. 2011 uvádí, že centralizovaný index Summon indexuje více než 35 repozitářů s otevřeným přístupem a přes 90 institucionálních repozitářů a digitálních sbírek svých klientů.
Vzhledem k tomu, že údaje o jednom dokumentu může Summon získávat z více zdrojů, vytváří se sloučený záznam, do něhož jsou z každého zdroje přebírána ta metadata, která jsou považovaná za nejsilnější. Bez ohledu na zdroj informací Serial Solutions opravuje chyby v záznamech a data normalizuje, záznam je také dále obohacován např. údaji z Ulrich´s.
Rozhraní Summon i využívání centralizovaného indexu je poskytováno jako hostovaná služba (software-as-a-service).
Při získávání lokálního obsahu je Summon schopen sklízet záznamy ze všech hlavních knihovních systémů, systémů pro správu digitálních sbírek a institucionálních repozitářů založených na typických schématech, jakými jsou např. MARC, Dublin Core, XML, EAD. Je schopen se také přizpůsobit lokálně vyvíjeným či nestandardním systémům, a to za předpokladu, že knihovna umí z těchto systémů vyexportovat záznamy. Summon podporuje pro sklízení a získávání obsahu různé metody, např. OAI-PMH a FTP.
Lokální data z knihovního systému jsou aktualizována 1x denně v noci, lokální data z repozitářů pak podle domluveného harmonogramu; možná je i denní aktualizace.
Summon index je pro vyhledávání otevřený a nevyžaduje počáteční autentizaci uživatele. Rozhraní Summon může spolupracovat s proxy serverem knihovny či jinou alternativní autentikační metodou, kterou knihovna užívá pro zpřístupnění licencovaného obsahu svým uživatelům. Využity mohou být i link-resolvery knihovny s cílem poskytnout uživateli přístup k plnému textu, který si knihovna předplácí.
Všichni zákazníci využívající Summon vyhledávají v jednom centralizovaném indexu. Při standardním nastavení Summon se uživateli na základě položeného dotazu zobrazují pouze záznamy dokumentů dostupných v dané knihovně (ať již jde o informace získané od vydavatelů a agregátorů nebo sklizené z lokálních zdrojů). Kliknutím na možnost Add Result Beyond Your Library´s Collection se ve výsledcích navíc zobrazí výsledky z celého centralizovaného indexu, výjimku tvoří pouze záznamy získané sklízením katalogů cizích knihoven.
Knihovny si mohou samy nastavit, zda chtějí ve svém rozhraní uživatelům umožnit prohledávat i digitální sbírky a institucionální repozitáře dalších knihoven, které jsou obsaženy v centralizovaném indexu Summon. Pokud toto nechtějí primárně nabídnout (tj. nechtějí, aby údaje z těchto sbírek byly automatickou součástí výsledků vyhledávání), nabídne se tento obsah až při kliknutí na zmíněnou volbu Add Result Beyond Your Library´s Collection.
V opačném "směru" knihovna nemůže v rámci komunity uživatelů centralizovaného indexu Summon omezit využívání obsahu získaného z jejích digitálních sbírek a repozitářů pouze na svou "aplikaci", tj. tyto informace jsou v indexu dostupné pro všechny zapojené instituce. Vyhledávání v Summon probíhá na úrovni metadat i plného textu, nalezené záznamy jsou uživateli vraceny seřazené podle relevance. Summon využívá vlastní algoritmus s rozdílnými váhami přiřazenými k různým polím s metadaty. Při hledání v plnému textu relevanci ovlivňuje např. vzdálenost termínů a frekvence. Pro různé druhy obsahu mohou být uplatňovány různé parametry, při výpočtu relevance u časopiseckého článku se např. zohledňuje, zda byl článek publikován v recenzovaném časopisu a kolikrát byl článek citován. Dalším kritériem při stanovování relevance je aktuálnost nalezeného obsahu.
Centralizovaný index Summon je možné díky API rozhraní využívat i mimo prostředí Summon. Villanova University a několik dalších univerzity např. kombinuje centralizovaný index Summon s prezentační vrstvou VuFind, v Dánsku je využíván v open source rozhraní Summa (State and University Library) a lze jej implementovat i do komerčního rozhraní Primo, jak je užíván v tzv. Sherlock Search v Claremont College Library.
První verzi WorldCat Local OCLC zveřejnilo v listopadu 2007. I v případě tohoto systému probíhal vývoj v těsné spolupráci s knihovní komunitou, konkrétně s University of Washington. V roce 2009 OCLC WorldCat Local rozšířilo a uzavřelo další partnerství s cílem získat pro WorldCat Local i obsah na úrovni článků.
Citace článků jsou pro WorldCat Local získávány několika způsoby. Přímo do centrálního indexu WorldCat Local plynou údaje na základě smluv s vydavateli periodik, druhým zdrojem jsou agregátoři, kteří poskytují své citace článků volně všem zákazníkům WorldCat Local. Třetí zdroj představuje databáze WorldCat obsahující téměř čtyři miliony citací článků. Obsah získaný výše zmíněnými cestami mohou využívat všichni zákazníci WorldCat Local. Pro WorldCat Local je obsah získáván také na základě přímých smluv s poskytovateli databází, přičemž části těchto poskytovatelů přístup ke svým zdrojům nabízí i prostřednictvím OCLC. Na základě smluv uzavřených s OCLC tito poskytovatelé umožňují, aby část obsahu předplácených bází byla indexována a obsažena v centrálním indexu WorldCat Local. Tyto informace jsou pak dostupné pouze pro zákazníky WorldCat Local, kteří si příslušné zdroje předplácejí, a to bez ohledu na platformu zvolenou v dané knihovně pro nativní přístup k vybrané bázi. Zapojená knihovna má vždy kontrolu nad tím, které zdroje mohou být v jejím vyhledávání ve WorldCat Local výsledně aktivovány.
Aktuální přehled databází a kolekcí zapojených do WorldCat Local s informací, zda je zdroj integrovaný do centrálního indexu či zapojený vzdáleně, je dostupný na stránkách OCLC (http://www.oclc.org/worldcatlocal/overview/content/dblist/default.htm). Obdobně na svých stránkách OCLC prezentuje seznam integrovaných periodik (http://www.oclc.org/worldcatlocal/overview/content/journals.htm).
Obdobně jako tvůrci ostatních již zmíněných centrálních indexů i WorldCat Local do svého indexu zahrnuje údaje z repozitářů s otevřeným přístupem, které jsou samozřejmě volně přístupné pro všechny zákazníky WorldCat Local. Ve WorldCat Local je dál možné nalézt metadata e-knih poskytnutá komerčními agregátory a vydavateli či pocházející z masové digitalizace např. od Google.
WorldCat Local využívá proxy servery aplikované v knihovnách pro poskytování vzdáleného přístupu k licencovanému obsahu, spolupracuje s link-resolvery knihovny a znalostní bází WorldCat jako prostředníkem k licencovanému obsahu; zákazníci musí mít záznamy jednotek svých periodických publikací uvedené ve WorldCat.
Knihovny mohou zapojit své lokální zdroje tím, že zpřístupní své záznamy v katalogu WorldCat. V případě, že záznamy z lokálního katalogu dosud ve WorldCat nebyly obsaženy, nejsou ani součástí vyhledávání. Knihovny mají možnost požádat o jednorázové stažení aktuálních záznamů ze svého knihovního systému do databáze WorldCat, kde jsou záznamy aktualizovány a indexovány, součástí lokálních záznamů v katalogu musí být číslo OCLC. Obsah dalších lokálních zdrojů knihovny může být sklizen a získaná metadata jsou následně převedena do formátu MARC, který je základním schématem pro WorldCat. OCLC také nabízí speciální nástroj WorldCat Digital Collection Gateway pro systémy pro správu digitálního obsahu a digitální repozitáře kompatibilní s OAI-PMH, tento nástroj ulehčí knihovnám import a publikování tohoto obsahu ve WorldCat a WorldCat Local.
Hodnocení relevance ve WorldCat Local zohledňuje mimo jiné, ve kterých polích z MARC záznamu byly hledané termíny nalezeny, přičemž polím autor, název a předmět je dávána větší váha. Svou roli hraje i aktuálnost a počet knihoven, jež ve WordCat uvádějí své fyzické lokace. Výsledky jsou tříděny a vraceny nejen podle relevance, ale také s ohledem na konkrétní knihovnu. Knihovny si však mohou ze schématu pro hodnocení relevance kritérium upřednostňující "jejich vlastní fond" vyloučit.
WorldCat Local je dostupný ve dvou verzích. Vedle stejnojmenné "plné" verze mohou knihovny využívat i "odlehčenou variantu" WorldCat Local "quick start". WorldCat Local oproti WorldCat Local "quick start" nabízí flexibilitu při integraci řady knihovních systémů, možnost zužovat výsledky dotazů podle lokace knihovny, respektive pobočky, řazení podle relevance zohledňující sbírky dalších knihoven v rámci konsorcia a další možnosti sdílení zdrojů kromě WorldCat Resource Sharing nebo ILLiad. WorldCat Local "quick start" je dostupný bez dalších poplatků v případě, že knihovna dodává záznamy svých jednotek do katalogu WorldCat a předplácí službu FirstSearch. Bez ohledu na zvolenou verzi je WorldCat Local vždy hostován společností OCLC.
Literatura
BREEDING, Marshal. Library web-scale. Computers in libraries. 2012, January / February, s. 19-21. ISSN 1041-7915.
LUPRICH, Jan; MILOVANOVIC, Marina. EBSCO Discovery Service aneb Digitální knihovna "all inclusive". 2011. Předneseno na 12. slovenské bibliografické konferenci (Martin, 2011).
POSPÍŠILOVÁ, Jindřiška; KOŠŤÁLOVÁ, Karolína; NEMEŠKALOVÁ, Hana. Katalogy nové generace : analýza vybraných systémů z pohledu uživatele. 1. vyd. Praha : Národní knihovna České republiky, 2009. 66 s. ISBN 978-80-7050-579-3.
VAUGHAN, Jason. Chapter 2 : OCLC WorldCat Local. Library Technology Reports. 2011, vol. 47, no. 1, s. 12-21. ISSN 0024-2586.
VAUGHAN, Jason. Chapter 3 : Serial Solutions Summon. Library Technology Reports. 2011, vol. 47, no. 1, s. 22-29. ISSN 0024-2586.
VAUGHAN, Jason. Chapter 4 : Ebsco Discovery Services. Library Technology Report. 2011, vol. 47, no. 1, s.30-38. ISSN 0024-2586.
VAUGHAN, Jason. Chapter 5 : Ex Libris Primo Central.Library Technology Reports. 2011, vol. 47, no. 1, s. 39-47. ISSN 0024-2586.
CITACE:
Coufalová, Jindřiška; Košťálová,
Karolína; Šťastná, Petra. Zkušenosti
služeb Národní knihovny s centrálními indexy a web-scale discovery
systémy.
Knihovna plus [online]. 2012, č. 1 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovnaplus121/coufal.htm>.
ISSN 1801-5948.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |