|obsah| |index autorů | | index názvů | | index témat | | archiv |
Knihovna
2009, ročník 20, číslo 1, s. 38-57
Marie Balíková / Národní knihovna ČR / e-mail: marie.balikova@nkp.cz
Abstrakt:
Vícejazyčný systém agregace informací (M-CAST, Multilingual Content Aggregation System) umožňuje tvorbu digitálních knihoven prostřednictvím agregace dat dostupných v různých formátech a z různých zdrojů. Systém M-CAST je založen na výsledcích projektu TRUST – Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies (Vícejazyčný sémantický a kognitivní mechanismus vyhledávání textů využívající sémantické technologie, IST-1999-56416), který byl financován z Pátého rámcového programu EU pro rozvoj vědy a výzkumu Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies. Vyhledávací stroj TRUST umožňoval vyhledávání ve čtyřech jazycích (francouzštině, italštině, polštině a portugalštině). Systém je nyní obohacen o dva další jazyky: angličtinu a češtinu. Jazykové zdroje systému TRUST jsou aktualizovány a v systému nadále využity. Systém vyhledávání je obohacen o možnost zúžení dotazu pomocí standardního mezinárodního desetinného třídění (MDT), celosvětově používaného v knihovních systémech. V příspěvku je nastíněna možnost budoucího využití systému M-CAST v českém prostředí.
Abstract:
The Multilingual Content Aggregation System (M-CAST) will allow for the development of Digital Libraries by aggregating digital data available in different formats and locations. M-CAST will be based on the outcome of the TRUST – Multilingual Semantic and Cognitive Search Engine for Text Retrieval Using Semantic Technologies (IST-1999-56416) project financedbythe5th European Union Framework Programme for RTD. The TRUST search engine is developed for 4 languages (French, Italian, Polish and Portuguese). Two other languages modules will be added: English and Czech. The TRUST language resources will be used and updated. Searching system will enable to narrow the search using the standard Universal Decimal Classification(UDC)appliedin library cataloguing systems worldwide. A potential application of the M-CAST system within the Czech context is discussed.
Úvodní poznámka
Příspěvek je přepracovanou a zkrácenou verzí studie Systém M-CAST (Multilingual Content Aggregation System – Vícejazyčný systém agregace informací) publikované ve sborníku Dotazování v přirozeném jazyce.
Příspěvek je rozdělen do několika základních tematických celků. Úvodní kapitola obsahuje základní charakteristiku systému M-CAST. Ve druhé kapitole se můžeme seznámit s architekturou systému, ve třetí je charakterizován proces indexace. Čtvrtá kapitola je věnována problematice vyhledávání, pátá kapitola přináší informace o testování a hodnocení systému M-CAST. V závěrečných kapitolách (6 a 7) jsou nastíněny možnosti aplikace systému v českém prostředí a možnosti jeho dalšího vývoje.
Systém M-CAST je vícejazyčným indexovacím a vyhledávacím nástrojem umožňujícím tvůrcům obsahu integrovat a prohledávat rozsáhlé soubory textů včetně multimédií, jako jsou internetové knihovny, informační zdroje nakladatelství a tiskových agentur nebo databáze vědeckých informací poskytující informační služby široké odborné i laické veřejnosti.
Představuje sofistikovaný dialogový(nehlasový) systém s prvky umělé inteligence založený na bázi sémantických technologií. Používá metodu dotazování v přirozeném jazyce, která je součástí technologie zpracování přirozeného jazyka a uživateli nabízí možnost klást/formulovat dotaz celou větou.
Zpracování přirozeného jazyka, jehož cílem je přesná a jednoznačná sémantická reprezentace textu, se odehrává ve všech jazykových rovinách: v morfologické, syntaktické, sémantické i pragmatické. Úspěšnost procesu vyhledávání je přímo závislá na kvalitě sémantické reprezentace textu, tokenizaci výchozích nestrukturovaných textů, kvalitní morfologické analýze a desambiguaci, tj. zjednoznačnění prvků přirozeného jazyka.
Systém M-CAST umožňuje v současné době sémantické vyhledávání v šesti jazycích: ve francouzštině, portugalštině, italštině, polštině, angličtině a češtině; nezávislost struktur formálního jazyka na konkrétních jazycích tím vystupuje do popředí.
Čeština je ve srovnání s ostatními jazyky, zejména s angličtinou, komplikovaným jazykem s bohatou morfologickou strukturou. Procesy jako např. lematizace, tj. převádění výrazů na základní slovníkový tvar, a derivace – metoda sloužící k tvorbě všech odvozenin ze základního slovníkového tvaru, dále pak morfologická, syntaktická i sémantická desambiguace jsou mnohem náročnější než v jiných jazycích.
Systém M-CAST se řadí do rodiny interaktivních dialogových vyhledávacích systémů, jejichž konečným cílem je v podstatě opuštění umělých selekčních jazyků jakožto vyhledávacích nástrojů. Schopnost uživatele komunikovat s vyhledávacím systémem formou celých vět odpovídá současným trendům ve vývoji interaktivních vyhledávacích systémů na bázi sémantických technologií. Vyhledávání je jednoduché a rychlé. Uživatel nemusí znát žádný formální dotazovací jazyk, navíc existují dotazy, které se v přirozeném jazyce formulují snadno, jejich konstrukce je však v dotazovacích jazycích obtížná ("negativní" dotazy nebo dotazy s obecnou kvantifikací).1
Systém M-CAST nabízí netradiční způsob vyhledávání v databázích primárních (ale i sekundárních) informačních zdrojů. Vyhledáváme-li v těchto databázích tradičním, "klasickým" způsobem, zadaný výraz je vyhledán jako textový řetězec. Výsledkem dotazu je seznam dokumentů, ve kterých se zadané výrazy vyskytují. Nevýhodou tohoto postupu je, že uživatel je mnohdy přesycen množstvím odkazů na dokumenty, byť různým způsobem zhodnocených, které musí konzultovat, aby získal požadovanou informaci. Při netradičním způsobu vyhledávání (dotazování v přirozeném jazyce) je vyhledávaný výraz, kterým je v tomto případě celá věta, analyzován a obohacen o další sémantické informace ve strojem srozumitelné podobě. Výsledkem vyhledávání je v tomto případě jednoznačná konkrétní odpověď, nebo úryvek textu obsahující konkrétní odpověď a možnost zasazení těchto odpovědí do širšího kontextu (vizualizace zdrojové stránky).
Systém M-CAST jako ostatní vyhledávací systémy na bázi sémantických technologií je určen široké veřejnosti i specialistům. Ukazuje se, že intenzivní využití sémantických technologií v procesu vyhledávání je perspektivní metodou jak pro analýzu dotazů a indexovaných textů, tak pro extrakci odpovědí.
Systém M-CAST je výsledkem mezinárodní kooperace: na vývoji systému se podílely firmyInfovide-MatrixS.A.aTiPsp.zo.o.(Polsko), Synapse Développement SARL (Francie), Priberam Informática Lda. (Portugalsko), Expert System S.p.A (Itálie) a Vysoká škola ekonomická v Praze. Systém byl testován v Polské internetové knihovně a Národní knihovně České republiky.
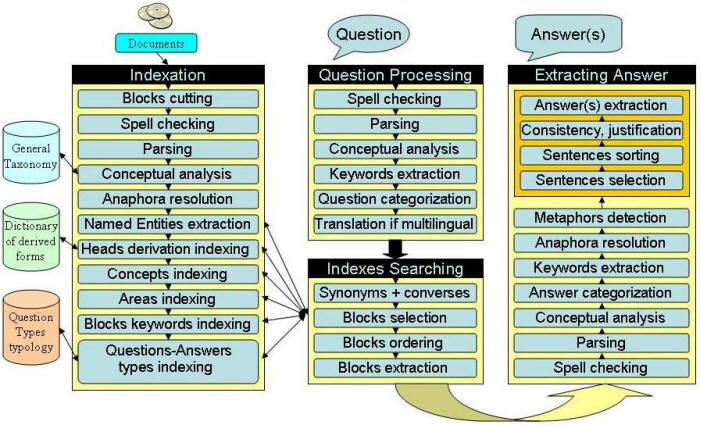
Pro kvalitu indexovacího a vyhledávacího systému založeného na sémantických technologiích jsou důležité tři komponenty: pro funkčnost systému je rozhodující velikost a reprezentativnost databáze indexovaných dokumentů, funkčnost a výkonnost jednotlivých komponentů indexovacího a vyhledávacího stroje M-CAST a funkčnost portálu M-CAP. Architektura systému je na všech stupních modulární. Po technické stránce vychází architektura systému M-CAST z tradiční třívrstvé architektury a obsahuje vrstvu klientskou, tj. browser, vrstvu aplikační, tj. web server a část business logic, a vrstvu datovou, tj. lingvistický procesor, který se skládá ze základních procesních prvků, tj. lingvistických modulů. Třívrstvý model podporuje vyšší úroveň stability; klient pracuje pouze s uživatelským rozhraním, datové a aplikační služby jsou od sebe odděleny do samostatných logických modulů. Jde o síťovou architekturu, kde komunikace mezi jednotlivými vrstvami je umožněna pomocí rozhraní webových služeb. Lingvistický procesor je dostupný pomocí rozhraní webové služby a může být používán jako vzdálený flexibilní zdroj. Portál M -CAST pracuje na platformách J2EE a Tapestry. Aplikace těchto technologií otevírá celou řadu možností integrace s jinými informačními technologiemi, usnadňuje další rozvoj systému a zmenšuje nároky na jeho údržbu.
Lingvistické moduly pro jednotlivé jazyky byly vytvářeny na sobě nezávisle; reflektují potřeby jednotlivých národních jazyků, sdílejí však základní obecné principy aplikované při automatizovaném zpracování přirozeného jazyka.
Kvůli podstatným rozdílům mezi jednotlivými jazyky byl zvolen otevřený design, který umožňuje připojení dalšího jazyka pomocí oddělených zásuvných modulů (plug-ins). Lingvistický procesor používá lingvistické moduly k vyhledání jazykově neutrální reprezentace dotazu. Tato jazykově neutrální reprezentace dotazu je pak použita při vlastním procesu vyhledávání v rámci lingvistického procesoru. Každý lingvistický modul používá odpovídající lingvistické zdroje.
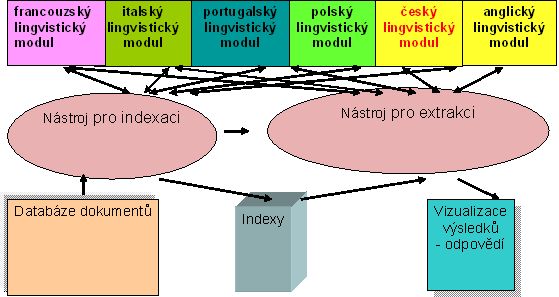
Obr. č. 1: Integrace lingvistických modulů v systému M-CAST
Složitost (maximální 2) struktury lingvistických modulů je patrná z následujícího schématu pro francouzský lingvistický modul vyvinutý francouzským partnerem, firmou Synapse Développement:
Obr. č. 2: Francouzský lingvistický modul
Český lingvistický modul byl vyvíjen paralelně s modulem polským. Na jeho vývoji se podílely polská firma TiP (garant polského modulu), portugalská Priberam Informática,jejíž programové nástroje byly použity pro zpracování obou nově připojených jazyků a Vysoká škola ekonomická v Praze. Základní lingvistickou datovou strukturu podporující funkce systému M-CAST představují formální definice předem vyčleněných kategorií dotazů a potenciálních odpovědí na ně v indexovaných textech. V systému M-CAST se rozlišuje 86 sémantických typů dotazů definovaných firmou Synapse Développement. Definice pro jejich rozpoznávání v češtině byly formulovány pomocí nástroje SintaGest (Priberam Informática).
Nutným předpokladem fungování vzorců pro rozpoznávání typů dotazů a odpovědí je morfologická analýza indexovaných textů a pokládaných dotazů, která se provádí pomocí morfologického analyzátoru.
Morfologický analyzátor češtiny používaný v českém lingvistickém modulu systému M-CAST a vyvinutý týmem doktorandů a studentů pod vedením Dr. P. Strossy je založen na slovníku, ve kterém je každému slovu přiřazen jeden ze vzorů ohýbání, a systému tabulek definujících jednotlivé vzory ohýbání. Z těchto dat je kompilována pracovní datová struktura efektivně uchovávající a rozpoznávající všechny tvary všech slov. Tabulky definující vzory mají odlišnou strukturu podle slovních druhů.3
Lingvistický procesor představuje technicky nejpokročilejší součást systému M-CAST. Obsahuje modul pro zpracování dotazů a modul vyhledávací a jeho úkolem je zpracovat dotazy z portálu M-CAST.
Funkčnost lingvistického procesoru (LP) systému M-CAST je zajištěna pomocí technologie webové služby. Používají se dvě kategorie rozhraní: první rozhraní souvisí s indexovacím modulem LP. Umožňuje indexovat dokumenty vyhledané ve vzdálených repozitářích a zpřístupnit je efektivním způsobem v průběhu vyhledávání. Druhé rozhraní umožňuje zpracování dotazů přímo v indexovaných dokumentech v modulech LP. Rozhraní jsou definována jazykem WSDL.
Integrační vrstva systému M-CAST zajišťuje metadata, sběr dat (harvesting) a předání těchto údajů LP k indexování pomocí rozhraní webové služby.
V tomto modulu (v této vrstvě) probíhají dva procesy:
Procesy jsou řízeny programem Scheduler, který je v podstatě srdcem systému M-CAST. Tato služba iniciuje a zajišťuje indexační proces v rámci systému. Program Scheduler organizuje pořadí jednotlivých úkolů, které musejí být realizovány v rámci systému M-CAST.
Prezentační vrstva systému M-CAST je modul odpovídající za uživatelské rozhraní pro kladení dotazů a za komunikaci se zbývajícími moduly. Architektura modulu je složitá, protože modul musí být schopen zajistit několik různých procesů souvisejících se službami systému M-CAST:
M-CASTu prohledávat paralelně několik instancí M-CAST systému, např. instanci Národní knihovny ČR a instanci Polské internetové knihovny (PBI). V tomto případě je uživatelův dotaz simultánně zpracováván v několika (předvolených) instancích systému M-CAST.
Schopnost portálu M-CAST vyhledávat ve více instancích poskytuje v podstatě neomezenou škálovatelnost (schopnost distribuovaného systému využívat dodatečné hardwarové zdroje pro uskutečnění většího počtu operací s daty).
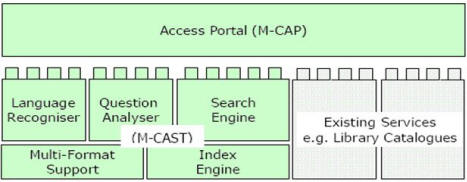
Portál M-CAST/M-CAP je schopen kombinovat různé aplikace a informační zdroje do jediné ucelené prezentace; uživatelé v různých rolích mohou vidět odlišný obsah dle svých přístupových oprávnění nebo svého profiluamohousiobsahpřizpůsobit.
Portál M-CAST/M-CAP je modulární; je koncipován tak, aby umožnil integraci stávajících vyhledávacích nástrojů používaných v dané instituci. Existují dva způsoby integrace portálu M-CAST/M-CAP do procesu vyhledávání dané instituce. Jednak lze obohatit stávající vyhledávací možnosti o rešeršní strategii dotazování v přirozeném jazyce a zvolit portál M-CAST/M-CAP jako základní nástroj.
Obr. č. 3: Portál M-CAST/M-CAP jako základní nástroj
Je však možný i obrácený postup: Instituce zahrne portál M-CAST/M-CAP jako součást stávajícího portálu.
Obr. č. 4: Ukázka možného zapojení systému M-CAST do stávajícího portálu instituce (ilustrativní ukázka)
Indexovací a vyhledávací stroj M-CAST je nyní koncipován jako nástroj pro extrahování odpovědí z dokumentů a korpusů umístěných na pevném disku; v budoucnu se počítá i s extrahováním odpovědí z internetu – z webových stránek nebo prostřednictvím klasických webových vyhledávačů (Google, MSN, AOL atd.).
Jako u jiných systémů na bázi sémantických technologií, tak i zde hraje důležitou roli velikost a reprezentativnost databáze indexovaných dokumentů, jejichž indexovaný obsah je uložen v interní databázi, ve které následně vyhledávají uživatelé. Tato velikost a reprezentativnost je do jisté míry měřítkem množství a kvality informací, které lze ve vyhledávacím systému najít. Systém M-CAST neindexuje všechny tištěné či elektronické dokumenty dostupné v daném oboru/daných oborech, protože informační zdroje zařazené do databáze M-CAST podléhají výběru podle předem stanovených kritérií.
Pro testovací fázi systému M-CAST zpřístupnila Národní knihovna databáze, které jsou součástí lokálního repozitáře, tedy instance M-CASTu používané Národní knihovnou. Jde o aplikace pracující s digitálními objekty:
Externím zdrojem pro testování byla Evropská ústava (europa.eu/constitution/), která obsahuje texty ve všech jazycích M-CASTu, slouží tedy k testování vícejazyčného modulu.
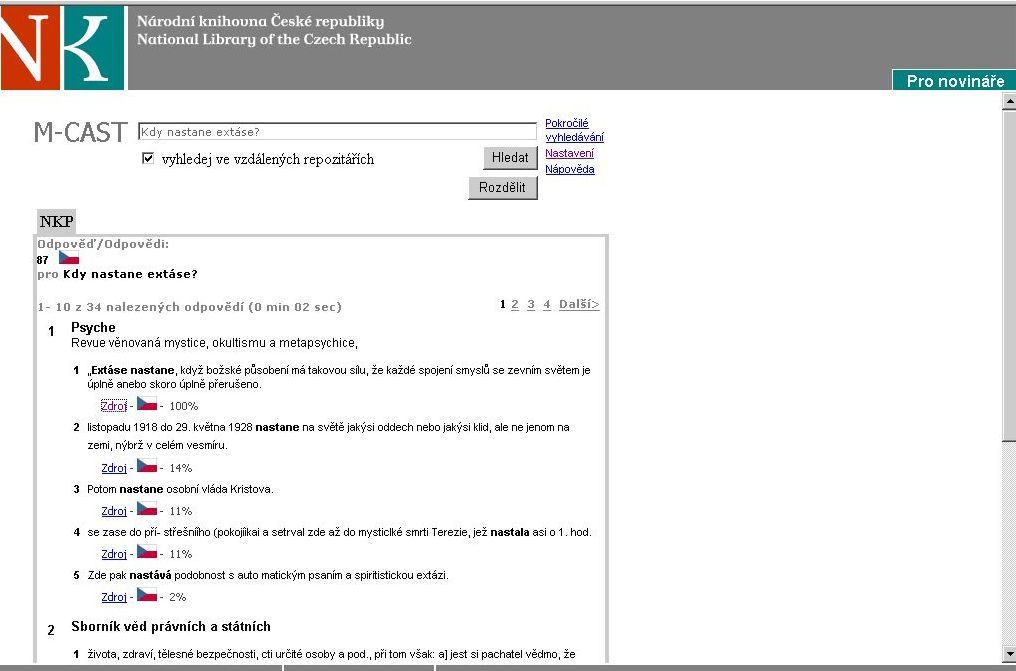
Obr. č. 5: Ukázka instance systému M-CAST v Národní knihovně
Instance M-CASTu používaná v Národní knihovně může být propojena i s dalšími instancemi systému, v současné době s instancí používanou v Polské internetové knihovně. Uživatel Národní knihovny může tedy vyhledávat i ve vzdáleném repozitáři, ve kterém jsou uloženy dokumenty zpřístupňované Polskou internetovou knihovnou.
Proces indexace probíhá ve všech lingvistických modulech podle stejných pravidel, extrahovaná data jsou stejné kategorie, zpracování těchto dat je tedy nezávislé na původním jazyce.
Základním předpokladem pro úspěšné indexování dokumentů je tokenizace, kdy je text rozložen na základní selekční jednotky a v textu jsou identifikována slova,mezery, interpunkce a začátky a konce vět; dále stemming (lematizace), kdy se odstraňuje zakončení slova a ponechává se kmen/kořen (slovní základ), resp. (při lematizaci) je určena pro každý slovní tvar jeho základní podoba; neméně důležitá je derivace, kdy se k základnímu tvaru slova generují jeho inflexní tvary.V textech se provádí morfologická desambiguace slovních tvarů, nevýznamová a nespecifická slova jsou pomocí negativního slovníku (slovníku stop slov) odstraněna; při indexaci textů se uplatňuje také stejná typologie dotazů a odpovědí, používá se tentýž analyzátor dotazů, aplikuje se ontologie TRUST apod. Texty jsou konvertovány do Unicode a rozděleny do textových kilobytových bloků, dochází tak k redukci velikosti indexů. Každý textový blok je podroben morfologické, syntaktické a sémantické analýze.
Indexace typů dotazů používaná v systému M-CAST je bezpochyby nejoriginálnějším prvkem systému Qristal, který vyvinul francouzský partner, firma Synapse Développement z Toulouse (dále Synapse Développement). Při analýze bloků, které se indexují, se označují eventuální odpovědi, například název funkce určité osoby ("pekař", "ministr", "ředitel kanceláře" ...), datum narození ("narozen 28. dubna 1958"), kauzální vazby ("kvůli množství sněhu", "vzhledem k náledí" ...), nebo příčinné vazby ("což způsobilo velké zmatky", "což umožnilo zvládnutí – řízení provozu” ...); blok je tudíž indexován tak, aby mohl dodat odpověď označeného typu.
Na základě získaných výsledků je budováno 8 různých indexů:
Uživatelův dotaz je podroben syntaktické a sémantické analýze. Je určen typ dotazu. Výsledek sémantické analýzy dotazu může být negativně ovlivněn tím, že prvky dotazu vytvářejí omezený kontext, neboť dotaz je nutně na rozdíl od dokumentů výrazně kratší.
Na základě sémantické analýzy dotazu jsou podle váhy stanovena významově důležitá klíčová slova, pivots. Při vyhledávání se používají tyto výrazy obohacené o synonyma, o odpovídající koncepty, a přiřazené k typu otázky. Po analýze dotazu jsou prohledávány všechny indexy a jsou vybrány textové bloky, které nejvíce odpovídají parametrům dotazu; z nich jsou vybrány jednotlivé relevantní odpovědi, u nichž je stanovena váha na základě statisticko-lingvistických metod a jejich pořadí.
Systém podporuje dva typy vyhledávání: jednoduché a pokročilé. Pro každý typ vyhledávání je určen speciální formulář.
Při jednoduchém vyhledávání se zapíše do vyhledávacího boxu dotaz, kterým může být otázka v přirozeném jazyce, např. "Kdy byly předány insignie Karlově univerzitě?", nebo skupina selekčních termínů, např. "život"; "láska", případně fráze, např. "hodně muziky za málo peněz". Systém M-CAST odpoví vytvořením stránky s výsledky, tj. nabídne přesnou odpověď na dotaz a seznam úryvků odpovědí. Nejvíce relevantní odpovědi jsou umístěny jako první.
Kromě jednoduchého vyhledávání umožňuje M-CAST provádět pokročilé vyhledávání, při kterém je možné zúžit "oblast vyhledávání" podle tří úrovní kategorií klasifikačního systému MDT.
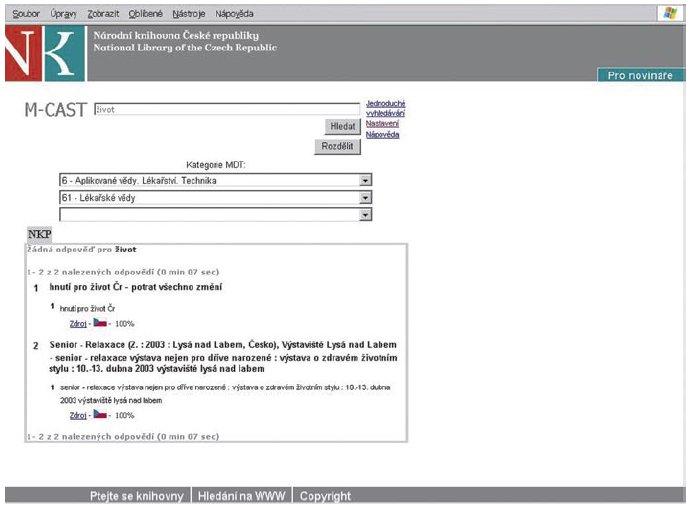
Obr. č. 6: Zúžení dotazu klasifikačním systémem MDT
Používá se v modulu jednoduchého vyhledávání.
Z pozice uživatele zpracovává systém M-CAST dotazy položené v přirozeném jazyce a nabízí přesné a jednoznačné odpovědi podpořené úryvky odpovědí, které jsou extrahovány z obsáhlé databáze indexovaných dokumentů. Jednou z nejdůležitějších podmínek úspěšnosti vyhledávání pomocí této metody je soubor dobře formulovaných otázek. Všechny informace, které jsou předmětem dotazu, musejí být obsaženy v databázi indexovaných dokumentů.
Dotazy používané při aplikaci metody dotazování v přirozeném jazyce jsou obvykle krátké, skládají se ze tří, čtyř slov. Dotaz formulovaný jako celá věta vede však automaticky k jeho prodlužování. Dlouhá otázka obsahující více klíčových významových prvků, "pivotů", může mít za následek, že při vyhledávání dokumentů jsou relevantní dokumenty odfiltrovány a nabídnuty dokumenty méně relevantní, obsahující více klíčových slov, avšak nerelevantních pro daný dotaz. Např. dotaz "Který umělecký soubor vystoupí na zahájení výstavy Velká Morava v Berlíně?" je příliš dlouhý, obsahuje 6 významových prvků; přímá odpověď, ani úryvek obsahující přímou odpověď na tento dotaz nebyly získány.
Systém M-CAST generuje na uživatelův dotaz celý soubor, blok odpovědí, který se skládá z:
Přímé odpovědi jsou většinou jmenné entity (jméno, místo, chronologický údaj, jmenné a slovesné fráze). Např. přímá odpověď na otázku "Co držel Zeus v pravé ruce?" je "bohyni vítězství".
Systém M-CAST generuje spolu s přímou odpovědí i odpovídající úryvek zdrojového dokumentu, který zasazuje přímou odpověď do potřebného minimálního kontextu. Úryvek obsahující přímou odpověď na výše uvedenou otázku je tedy: "V pravé ruce držel Zeus bohyni vítězství, jak se právě k němu sklání, chtíc hlavu jeho věncem ozdobiti; v levé držel žezlo."
Poslední část bloku odpovědi představuje potenciální vizualizace zdrojového dokumentu, tedy hypertextový odkaz vedoucí k příslušné stránce zdrojového dokumentu.
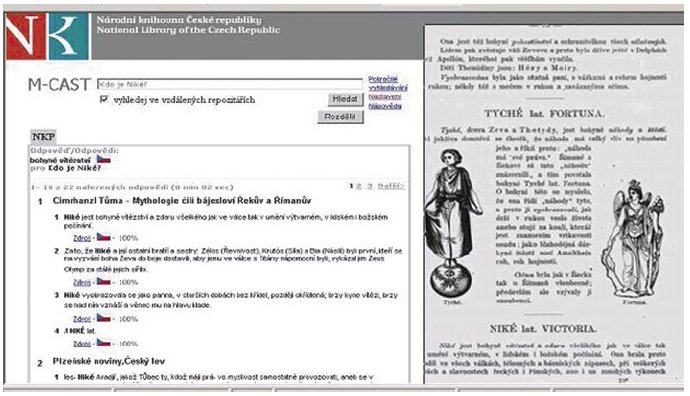
Obr. č. 7: Soubor odpovědí na dotaz Kdo je Niké

Obr. č. 8: Odpověď na dotaz Co tropili staří Čechové
Připojit nový jazyk, tedy vytvořit nový jazykový modul, je v systému M-CAST poměrně jednoduché; architektura systému zodpovídání dotazů je navržena tak, aby byla nezávislá na konkrétním jazyce. Ve všech jazykových modulech se používají stejné softwarové nástroje, např. SintaGest. Musí být upraveny a importovány jen jazykové zdroje nového jazyka (lexikon, tezaurus, ontologie, formální definiceotázek), aby souhlasily s používanými nástroji pro zpracování přirozeného jazyka. Pro vícejazyčné vyhledávání v systému M-CAST je jako propojovací jazyk použita angličtina.
Již bylo uvedeno, že obě testovací pracoviště neměla k dispozici rozsáhlou sbírku identických dokumentů ve všech jazycích M-CASTu. Bylo tedy zvoleno náhradní řešení a tato funkčnost systému M-CAST byla testována na textu Evropské ústavy. Pro tyto účely byl ve všech jazycích M-CASTu definováno 49 otázek, jako např.:
|
Questions in English |
Otázky v češtině |
| What is "Europe Direct” ? | Co je "Europe Direct”? |
| For how many years are elected the members of the European Parliament? | Na kolik let jsou voleni členové Evropského parlamentu? |
| What is the percentage for a qualifiedmajority? | Jaké procento tvoří kvalifikovanou většinu? |
| What is the capital of the European Investment Bank? | Jaký kapitál se přiděluje Evropské investiční bance? |
| What is "distraint-description"? | Co se rozumí "dokumentačně-zajišťovacím řízením"? |
| What is a "heavy goods vehicle"? | Co se rozumí "těžkým nákladním vozidlem"? |
| When did Portugal join the European Community? | Kdy přistoupila Portugalská republika k Evrop. společenstvím? |
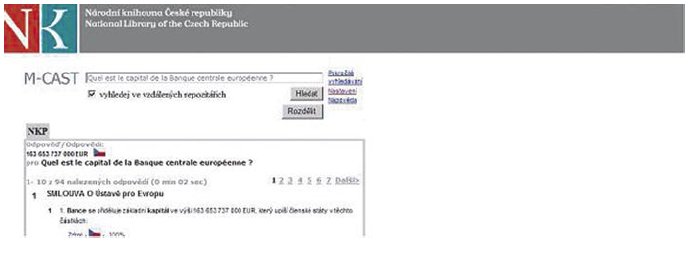
Obr. č. 9: Otázka v angličtině, odpověď v polštině
Obr. č. 10: Otázka ve francouzštině, odpověď v češtině
Cílem procesu testování a hodnocení systému bylo ověřit jeho funkčnost v plném provozu, prověřit odezvu systému a praktickými podněty a zkušenostmi přispět k odstranění všech případných nedostatků. Z hlediska uživatele bylo nutné se zaměřit také na proces vyhledávání jako takový a ověřit, je-li vyhledávání v systému M-CAST komplikované, nebo naopak snadné a intuitivní i pro méně zkušeného či nezkušeného uživatele.
Jedním z důležitých kritérií hodnocení kvality systému je dosažená odezva. Průměrná odezva prototypu systému M-CAST byla v době testování 4,9 sekundy.
Národní knihovna v letech 2004-2006 nevlastnila rozsáhlé soubory vícejazyčných dat soudobých dokumentů, proto byla fáze testování v Národní knihovně zaměřena na ověření funkčnosti systému M-CAST při vyhledávání informací ve sbírce indexovaných historických textů, a to v českém jazyce. Při testování bylo nutné vyřešit problémy spojené
s dotazováním v přirozeném jazyce aplikovaném při dotazování ve sbírce historických dokumentů, protože vzorové otázky pro M-CAP Národní knihovny byly původně definovány pro vyhledávání ve sbírkách současných textů. Bylo tedy nutné překonat problémy s dobově podmíněným pravopisem, s historickým slovníkem a složitostí historické syntaxe.
Výsledky testování byly výrazně ovlivněny kvalitou OCR textů. Původním cílem databáze Kramerius byla záchrana a zpřístupnění bohemikálních dokumentů tištěných na kyselém papíru, jejichž existence je ohrožena rozpadem (křehnutím) papírového nosiče. Špatný fyzický stav především starších novin a časopisů ovlivnil kvalitu výsledných obrazových souborů a výstup konverze OCR. Horší kvalita obrazových souborů se pak mnohdy negativně promítla do chybovosti při rozpoznávání během procesu konverze OCR do textové podoby. OCR texty obsažené v databázi Kramerius byly indexovány pro potřeby M-CASTu bez předchozích úprav: nebyly odstraněny nepřesnosti při segmentaci textu a chybějící nerozpoznané znaky, proto mnohdy některá slova, případně fráze nebyly identifikovány správně a docházelo tak k významovým posunům,případněvýsledek dotazu nedával smysl. Proces hodnocení byl ztížen tím, že systém M-CAST nabízí soubor/blok odpovědí, přičemž je všeobecně známo, že hodnocení komplexu odpovědí generovaných systémem je obtížnější než hodnocení jednotlivých typů odpovědí. Proto byla pro potřeby hodnocení systému vypracována tato speciální kategorizace opovědí:
případně systém negeneroval žádný úryvek jako odpověď na položený dotaz
| Přímá odpověď | ||
| správná | 10 % | 206 |
| nesprávná | 6 % | 124 |
| nepřesná | 31 % | 638 |
| žádná | 53 % | 1092 |
| celkem | 100 % | 2060 |
| Úryvek odpovědi | ||
| správná odpověď, 1.-5. úryvek | 73 % | 1520 |
| správná odpověď, ostatní | 15 % | 315 |
| nesprávná + žádná odpověď | 12 % | 225 |
| celkem | 100 % | 2060 |
Jak jsme již uvedli, základní metodou vyhledávání je dotaz v přirozeném jazyce, dotaz celou větou. Tento typ vyhledávání je dominantní v rozsáhlých sbírkách digitálních či digitalizovaných dokumentů, tedy v digitálních knihovnách. Digitální knihovna bývá definována jako integrovaný systém zahrnující soubor elektronických informačních zdrojů a služeb umožňující získávání, zpracovávání, vyhledávání a využívání informací v tomto systému uložených. Základní funkcí digitální knihovny je poskytnout uživatelům možnost jednotného přístupu k digitálním anebo digitalizovaným dokumentům, případně i k sekundárním informacím o tištěných primárních zdrojích.
Předpokládáme, že zdokonalená verze vyhledávacího systému M-CAST se uplatní i při procesu vyhledávání ve vznikající Národní digitální knihovně, jejímž cílem bude zpřístupnění digitálních a digitalizovaných knihovních dokumentů a která bude v budoucnu fungovat v širším kontextu České digitální knihovny.4 Následuje ukázka potenciální aplikace systému M-CAST v databázi Manuscriptorium.5
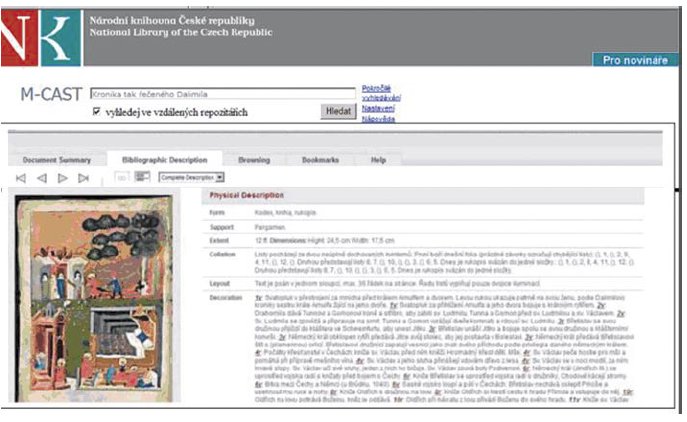
Obr. č. 11: Odpověď na dotaz Kdo přináší vdovám dřevo z lesa
Hybridní knihovna integruje klasickou knihovnu představovanou především tištěnými dokumenty a digitální knihovnu, obvykle s cílem zkvalitnění služeb uživatelům. Typickou ukázkou hybridní knihovny je v současné době Národní knihovna, která zpřístupňuje tradiční i elektronické dokumenty a byla jedním z testovacích pracovišť systému
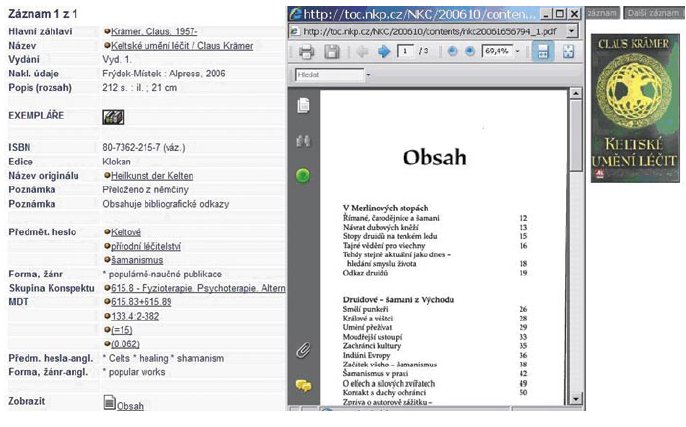
M-CAST. V průběhu vývoje a testování systému jsme se snažili rozšířit možnosti vyhledávání systému o prvky a postupy, které jsou typické pro hybridní knihovny. Výsledkem je výše zmíněná integrace klasifikačního systému MDT do procesu vyhledávání a možnost klást dotaz pomocí souboru selekčních termínů. Za účelem dalšího testování systému M-CAST aplikovaného v hybridních knihovnách využívá Národní knihovna výsledky jiného projektu, tj. Obohacení bibliografických záznamů o obsahy popisovaných dokumentů (projekt TOC – Table Of Content), který byl zahájen po schválení novely autorského zákona. Od poloviny r. 2006 existuje možnost obohatit bibliografické záznamy u odborné a populárně-naučné produkce o obsahy popisovaných dokumentů.
(projekt TOC – Table Of Content)
Dotaz je formulován formou fráze (souboru selekčních termínů) z obsahových údajů "králové a věštci". Výsledkem dotazu je úryvek odpovědi obsahující danou frázi:

Obr. č. 12: Úryvek odpovědi na dotaz frází Králové a věštci
Při vizualizaci zdrojového dokumentu získáme bibliografický záznam a prokliknutím na specifický formát "Obsah" získáme údaje obsahu dokumentu, ve kterých je uvedena fráze.
Obr. č. 13: Odpověď na dotaz frází Králové a věštci
Většina veřejných knihoven v současné době buduje a zpřístupňuje databáze regionálních osobností, událostí apod., které jsou ve většině případů budovány jako databáze plnotextové. Aplikace systému M-CAST v těchto databázích by umožnila klást uživatelům těchto knihoven dotazy v přirozeném jazyce.
Příklad potenciálního využití vyhledávacího systému M-CAST
dotazy: Kde studoval Bohumír Jaroněk?
Kde působila rodina Jaroňků?
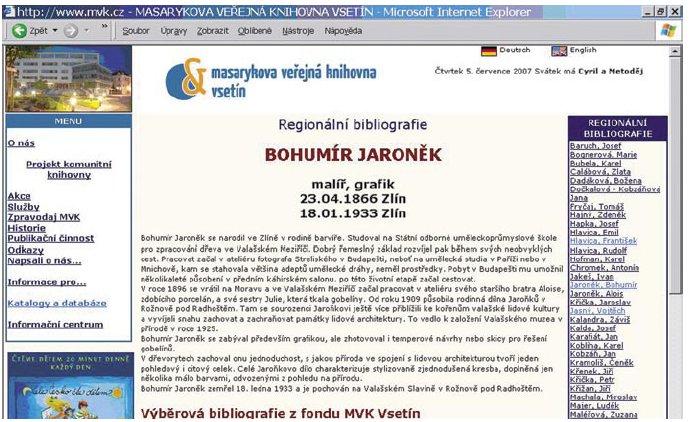
Obr. č. 14: Odpověď na dotaz Kde studoval Bohumír Jaroněk (ilustrativní ukázka)
Také další paměťové instituce jako archivy, galerie a muzea se podílejí na zpřístupnění národního kulturního dědictví, a to zpřístupněním informací na úrovni celých kolekcí či zpřístupněním informací o jednotlivých exponátech/artefaktech.
Pro záznamy popisovaných objektů, zvláště archivních a muzeálních, je typická kombinace strukturovaných selekčních prvků/přístupových bodů a rozsáhlého volného textu, který obsahuje další informace nezbytné pro badatelskou činnost.
Zpřístupnění má být efektivní, rychlé, komfortní a uživatelsky vstřícné. Efektivitu, rychlost a komfortní přístup zajišťují na jedné straně standardizované selekční prvky/přístupové body, tj. atributy, podle kterých můžeme informaci vyhledat. V níže uvedené ukázce záznamu o Janu Dočkálkovi zveřejněném na portálu Archives Canada jsou standardizované selekční prvky označeny jako "subjects".6
V popisných částech záznamu (ADMINISTRATIVE HISTORY/BIOGRAPHICAL SKETCH a COPE AND CONTENT), které obsahují informace v podobě volného textu, se za komfortní a uživatelsky vstřícný přístup považuje možnost klást otázky v přirozeném jazyce, tedy ptát se celou větou.
Příklad potenciálního využití vyhledávacího systému M-CAST
dotazy: Who was the leading officer in the Czechoslovak RedCross in England?
When did the communists come to power in Czechoslovakia?
When did Dockalek join the British Army?

Obr. č. 15: Odpověď na dotaz Who was the leading officer in the Czechoslovak RedCross in England(ilustrativníukázka)
Také záznamy českých archivů vynikají svým rozsahem. I zde by se mohla uplatnit zdokonalená verze systému M-CAST, zvláště v popisných částech, jako jsou dějiny, funkce, zaměření, činnost, "obecný kontext" aj.
Příklad potenciálního využití vyhledávacího systému M-CAST 7
dotazy:
Kdy bylo zřízeno ministerstvo železnic v Předlitavsku?
Co bylo úkolem ministerstva železnic?
Kdy zaniklo ministerstvo železnic v Předlitavsku?
Jaká byla struktura ministerstva?
Které sekce tvořily ministerstvo v roce 1912?
Z kterých sekcí sestávalo ministerstvo železnic v roce 1912?
Co bylo důležité pro hospodářský rozvoj koncem 19. století?
Které kompetence vykonávalo ministerstvo?
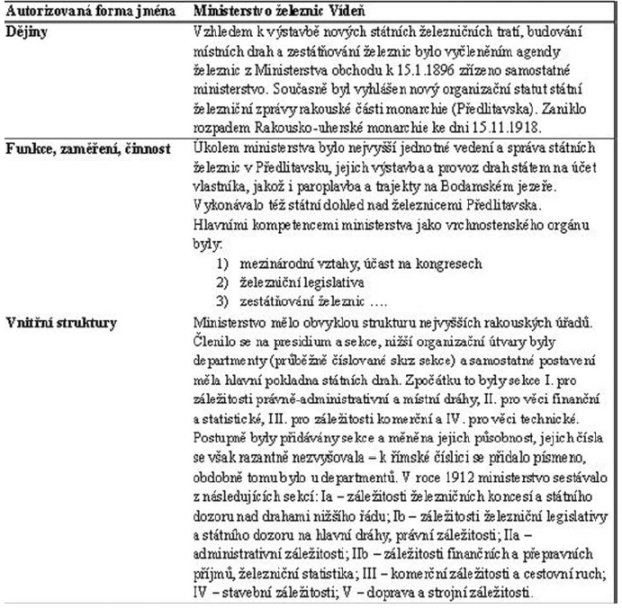
Obr. č. 16: odpověď na dotaz Kdy bylo zřízeno ministerstvo železnic v Předlitavsku (ilustrativní ukázka)
Národní knihovna ČR spravuje a zpřístupňuje nejenom sbírky knihovních fondů, ale i významnou kolekci řemeslně-uměleckých předmětů (glóbusy, hodiny, památkový nábytek, mříže, dveře, regály apod.), které jsou evidovány v Centrální evidenci sbírek Ministerstva kultury. I při vyhledávání informací obsažených v popisu jednotlivých kolekcí a jednotlivých exponátů lze potenciálně využít zdokonalený systém M-CAST.
dotazy:
Která sbírka byla nejstarším veřejným muzeem v českých zemích?
Kdo byl prvním prefektem sbírky historických glóbusů v Klementinské koleji?
Kdo sestrojil řadu hodin a mechanických automatů?
Kdy bylo matematické muzeum v Klementinu zrušeno?
Jak se nazývají nejkrásnější hodiny v matematickém muzeu v Klementinu?
Kde se nacházejí exponáty sbírky památkového nábytku Národní knihovny?
Kolik slunečních hodin se nachází na budovách Klementina?
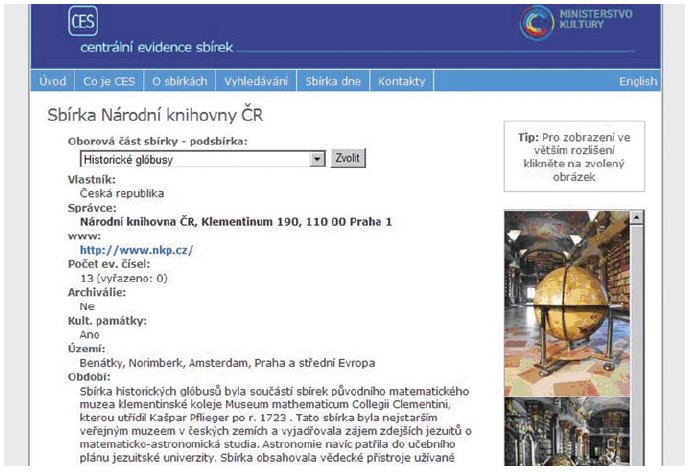
Obr. č. 17: Odpověď na dotaz Která sbírka byla nejstarším veřejným muzeem v českých zemích (ilustrativní ukázka)
Výsledky projektu M-CAST prokázaly možnosti uplatnění systému dotazů v přirozeném jazyce v prostředí digitálních i hybridních knihoven, a nově i v dalších paměťových institucích. Technologie zpracování přirozeného jazyka (natural language processing) se úspěšně uplatňují v oblasti analýzy dotazů, indexování dokumentů a extrakce otázek i ve vícejazyčném prostředí. Budoucím záměrem je rozvíjet a zlepšovat systém M-CAST v několika směrech. V současné době dokáže systém zodpovědět zhruba 70 % faktografických otázek a 30–40% nefaktografických otázek, a to ve francouzštině a portugalštině. Nyní je potřeba soustředit se na to, aby i ostatní jazyky dosáhly stejného procenta zodpovězených faktografických otázek, a současně zvýšit výrazně poměr zodpovězených nefaktografických otázek ve všech jazycích. V neposlední řadě je třeba zapojit do systému další jazyky (uvažuje se o němčině), včetně jazyků nelatinkového písma
(arabština, čínština). Projekt je v současné době formálně ukončen; nyní se hledají možnosti další kooperace a především financování. V Národní knihovně práce na projektu pokračují. V současné době se Národní knihovna zaměřuje na vytváření předpokladů pro aplikaci systému v hybridních knihovnách všech typů: probíhá výzkum dalších možností integrace klasifikačního systému MDT, připojují se údaje obsahů v rámci projektu
TOC. Dosavadní vývoj systému M-CAST ve srovnání s podobnými projekty ukazuje, že zvolená řešení jsou správná a perspektivní. Tímto však byla realizována první fáze: další vývoj vedoucí ke standardnímu a rutinnímu využití systému je teprve před námi.
Literatura
AMARAL, Carlos; LAURENT, Dominique. Implementation of a QA system in a real context : [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] [online]. [cit. 2007-10-19]. Dostupný z WWW:
BALÍKOVÁ, Marie. M-CAST in libraries : [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] [online]. [cit. 2007-10-19]. Dostupný z WWW: <http://knihovnam.nkp.cz/docs/telmemor/subject/M-CAST_in_libraries.ppt?PHPSESSID=e93ac950899817d81e359e42355fb5ae>.
CZERNIEJEWSKI, Borys. Multilingual Content Aggregation System based on TRUST Search Engine (M-CAST) : [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] [online]. [cit. 2007-10-19]. Dostupný z WWW: <http://knihovnam.nkp.cz/docs/telmemor/subject/M-CAST-project_presentation-final.ppt?PHPSESSID=e93ac950899817d81e359e42355fb5ae>.
LISEK, Sebastian. P2P networks for distributed queries : [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] [online]. [cit. 2007-10-19]. Dostupný z WWW: <http://knihovnam.nkp.cz/docs/telmemor/subject/M-CAST-P2P.ppt?PHPSESSID=e93ac950899817d81e359e42355fb5ae>.
STROSSA, Petr. Information Query Formulation in a Slavonic Language and its Automatic Processing : Experience from Polish and Czech in comparison to Western European Languages : [Paper Presented at TEL-ME-MOR/M-CAST Seminar On Subject Access, Prague, November 24, 2006] [online]. [cit. 2007-10-19]. Dostupný z WWW: <http://knihovnam.nkp.cz/docs/telmemor/subject/TEL-ME-MOR-PS.ppt?PHPSESSID=e93ac950899817d81e359e42355fb5ae>.
PALA, Karel. Počítačové zpracování přirozeného jazyka [online]. Brno, 2000. [cit. 2007- 10-19]. Dostupný z WWW:
<http://nlp.fi.muni.cz/poc_lingv/pala_zprac.pdf>.
BOLDIŠ, Petr. Vyhledávače : současné problémy a trendy vývoje. Knihovna plus [online]. 2005, č. 1 [cit. 2007-11-19]. Dostupný z WWW:
<http://knihovna.nkp.cz/knihovnaplus51/boldis.htm>.
STROSSA, Petr. Komunikace mezi člověkem a počítačem v přirozeném jazyce. Science WORLD [online]. Praha, 2004 [cit. 2007-11-19]. Dostupný z WWW: <http://scienceworld.cz/sw.nsf/ID/10D74E2E7ED7559EC1256F32005ACF20?OpenDocument>.
BALÍKOVÁ, Marie; STROSSA, Petr; VŘEŠŤÁLOVÁ, Dana. Dotazování v přirozeném jazyce : zkušenosti s aplikací prototypu systému M-CAST v českém prostředí. Praha : Národní knihovna České republiky, 2007. 78 s. ISBN 978-80-7050-537-3.
Poznámky
1 viz Strossa 2004
2 ve skutečnosti ne všechny lingvistické moduly uplatňují toto schéma v celé jeho komplexnosti
3 viz Strossa 2007, str. 43 a 45
4 viz http://www.ndk.cz/narodni-dk
5 obrázek zveřejněn se souhlasem správce databáze Manuscriptorium PhDr. Z. Uhlíře
6 viz http://www.archivescanada.ca/english/search/RouteRqst.asp?sessionKey=1143478259019_206_191_57_199&r=2&i=NA&l=0&v=0&coll=1&lvl=1&t=Dobson,+Will,+1914-1993
7 ukázka záznamu publikována se svolením autora Ing. Miroslava Kunta (NA)
CITACE:
Balíková, Marie. Systém M-CAST v českém kontextu. Knihovna [online]. 2009, roč. 20, č. 1, s. 38-57 . Dostupný z WWW: <http://knihovna.nkp.cz/knihovna91/balik.htm>. ISSN 1802-8772.
![]()
| nahoru | |obsah| | archiv | | domů |
| index autorů | | index názvů | | index témat |